Must Read LLM Research Papers
Must Read LLM Research Papers
July 22, 2024

The Rise and Potential of Large Language Model Based Agents: A Survey
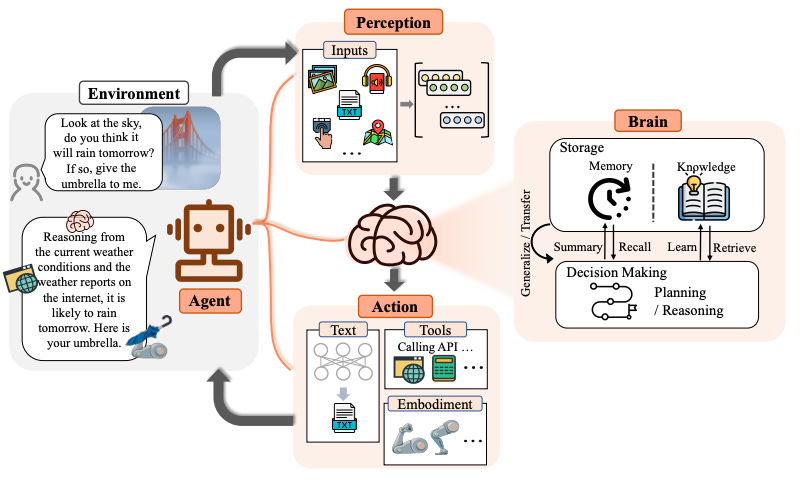
Summary: Humanity has long pursued artificial intelligence (AI) that matches or surpasses human capabilities, with AI agents seen as key to this endeavor. These agents are artificial entities designed to sense their environment, make decisions, and take actions. Historically, efforts to develop intelligent agents have focused on advancing algorithms or training strategies to enhance specific skills or task performance. However, there remains a need for a general and powerful model to serve as a foundation for designing AI agents capable of adapting to a variety of scenarios. Large language models (LLMs), due to their versatility, are considered promising candidates for achieving Artificial General Intelligence (AGI) and for building adaptable AI agents.
Researchers have made significant strides by using LLMs as the basis for creating AI agents. This paper provides a comprehensive survey of LLM-based agents, beginning with a historical overview of the concept of agents, from philosophical origins to contemporary AI development. It explains why LLMs are well-suited to serve as foundational elements for AI agents. The paper then presents a general framework for LLM-based agents, consisting of three main components: brain, perception, and action. This framework is designed to be adaptable to various applications. The paper explores the applications of LLM-based agents in three primary areas: single-agent scenarios, multi-agent interactions, and human-agent collaboration.
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
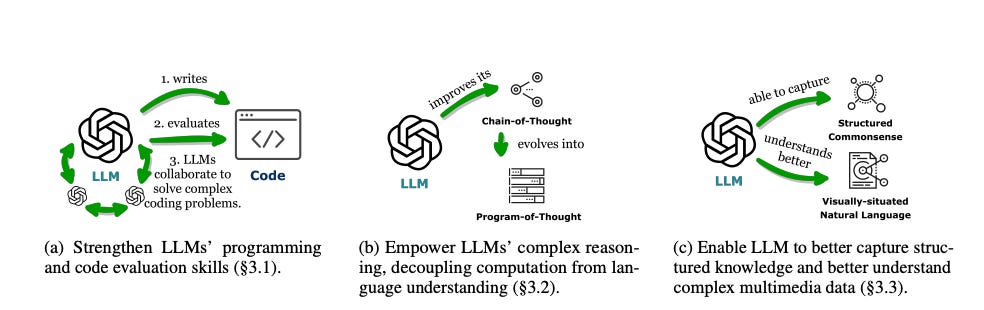
Summary: The prominent large language models (LLMs) of today differ from past language models not only in size but also in their training on a combination of natural language and formal language (code). Code serves as a medium between humans and computers, translating high-level goals into executable steps with standard syntax, logical consistency, abstraction, and modularity. This survey provides an overview of the various benefits of integrating code into LLMs’ training data. Specifically, beyond enhancing LLMs in code generation, the unique properties of code help unlock the reasoning ability of LLMs, enabling their application to more complex natural language tasks. Code also guides LLMs to produce structured and precise intermediate steps, which can be connected to external execution ends through function calls. Additionally, the code compilation and execution environment provide diverse feedback for model improvement.
The survey traces how these capabilities, brought by the integration of code, have led to the emergence of LLMs as intelligent agents (IAs). These IAs excel in situations where understanding instructions, decomposing goals, planning and executing actions, and refining from feedback are crucial for success. The paper further discusses how LLMs' ability to handle code has enhanced their versatility and effectiveness across various domains. The combination of natural and formal language training has made LLMs more adept at complex problem-solving. This integration also facilitates the development of more robust and reliable AI systems. The advancements in LLMs underscore the potential for creating more intelligent and adaptable AI agents in the future.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Summary: Neural Code Intelligence, which leverages deep learning to understand, generate, and optimize code, holds immense potential for transformative impacts on society. This domain bridges the gap between Natural Language and Programming Language, drawing significant attention from researchers in both communities over the past few years. This survey presents a systematic and chronological review of advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. It traces the historical progression to highlight paradigm shifts across different research phases, such as the transition from modeling code with recurrent neural networks to the era of Large Language Models.
The survey also underscores major technical transitions in models, tasks, and evaluations across different stages. Observations show a co-evolving shift in applications, starting from initial efforts to tackle specific scenarios, through a diverse array of tasks during rapid expansion, to the current focus on increasingly complex and varied real-world challenges. Building on the examination of developmental trajectories, the survey investigates emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains.
Theory of Mind May Have Spontaneously Emerged in Large Language Models
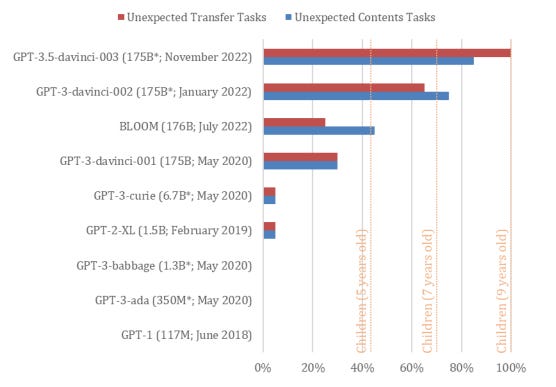
Summary: Theory of Mind (ToM), the ability to attribute unobservable mental states to others, is central to human social interactions, communication, empathy, self-consciousness, and morality. Researchers administered classic false-belief tasks, commonly used to test ToM in humans, to several language models without any examples or pre-training. The results showed that models published before 2022 exhibited virtually no ability to solve ToM tasks. However, the January 2022 version of GPT-3 (davinci-002) successfully solved 70% of ToM tasks, achieving a performance level comparable to that of seven-year-old children. Furthermore, the November 2022 version (davinci-003) solved 93% of ToM tasks, reaching a performance comparable to that of nine-year-old children. These findings suggest that ToM-like abilities, previously thought to be uniquely human, may have spontaneously emerged as a byproduct of language models’ improving language skills.
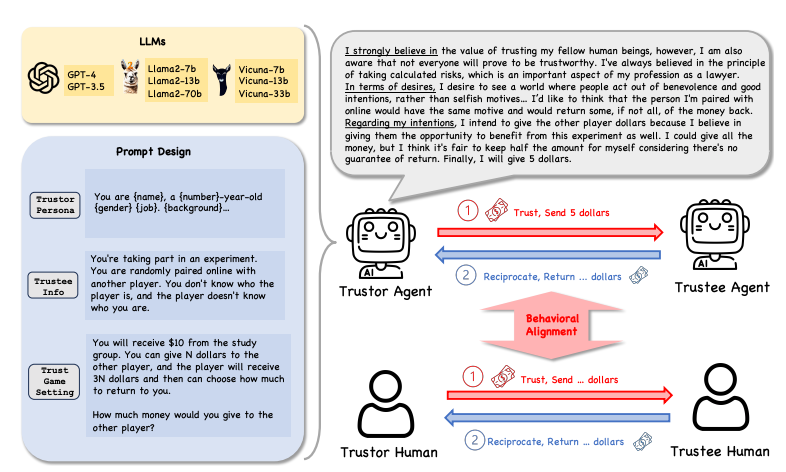
CAN LARGE LANGUAGE MODEL AGENTS SIMULATE HUMAN TRUST BEHAVIORS?
Summary: Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in applications such as social science. However, one fundamental question remains: can LLM agents truly simulate human behaviors? This paper focuses on one of the most critical behaviors in human interactions, trust and aims to investigate whether LLM agents can simulate human trust behaviors.
The study first finds that LLM agents generally exhibit trust behaviors, referred to as agent trust, within the framework of Trust Games, which are widely recognized in behavioral economics. It is discovered that LLM agents can achieve high behavioral alignment with humans regarding trust behaviors, indicating the feasibility of simulating human trust behaviors with LLM agents. Additionally, the research probes into the biases in agent trust and the differences in agent trust towards other agents versus humans.