Top AI papers of the week

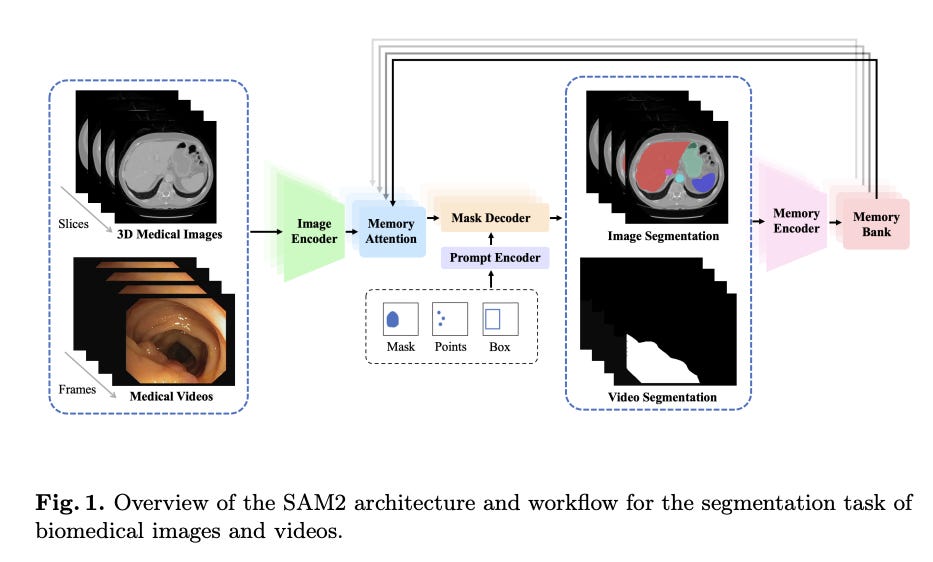
Unleashing the Potential of SAM2 for Biomedical Images and Videos: A Survey
Summary: Recent advancements in segmentation foundational models have emerged as a significant force in the field of computer vision, introducing a variety of previously unexplored capabilities across a wide range of natural images and videos. Notably, the Segment Anything Model (SAM) marks a significant expansion of the prompt-driven paradigm into the domain of image segmentation. The recent introduction of SAM2 further extends the original SAM to operate in a streaming fashion and demonstrates strong performance in video segmentation. However, due to the substantial differences between natural and medical images, the effectiveness of these models on biomedical images and videos remains under investigation. This paper provides an overview of recent efforts to apply and adapt SAM2 to biomedical images and videos. The findings suggest that while SAM2 shows potential in reducing annotation burdens and enabling zero-shot segmentation, its performance varies across different datasets and tasks.
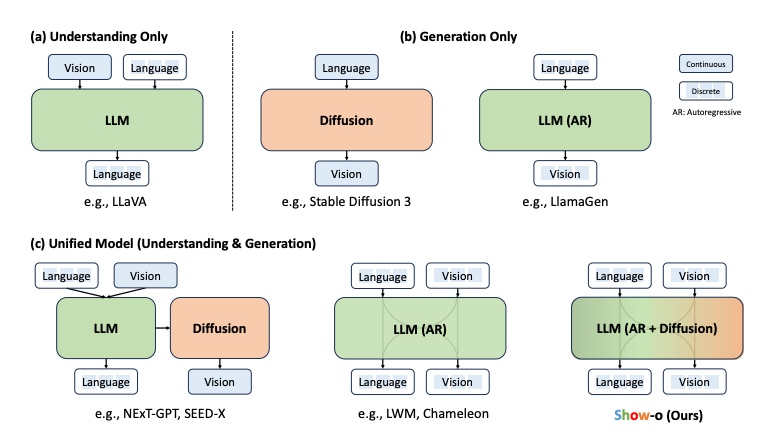
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Summary: A unified transformer model, named Show-o, is introduced, which integrates multimodal understanding and generation. Unlike fully autoregressive models, Show-o combines autoregressive and discrete diffusion modeling to adaptively manage inputs and outputs across various and mixed modalities. This unified model is versatile, supporting a wide array of vision-language tasks, including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Show-o consistently demonstrates performance that is comparable to or better than existing individual models, even those with an equivalent or larger number of parameters specifically designed for either understanding or generation. This underscores its potential as a next-generation foundational model.
Scalable Autoregressive Image Generation with Mamba
Summary: AiM, an autoregressive (AR) image generative model based on the Mamba architecture, is introduced. AiM leverages Mamba, a novel state-space model known for its exceptional performance in long-sequence modeling with linear time complexity, to replace the commonly used Transformers in AR image generation models. This approach aims to achieve both superior generation quality and enhanced inference speed. Unlike existing methods that adapt Mamba for handling two-dimensional signals via multi-directional scanning, AiM directly employs the next-token prediction paradigm for autoregressive image generation. This strategy avoids the need for extensive modifications to enable Mamba to learn 2D spatial representations. By implementing straightforward yet strategically targeted modifications for visual generative tasks, AiM retains Mamba's core structure, fully utilizing its efficient long-sequence modeling capabilities and scalability. AiM models are provided in various scales, with parameter counts ranging from 148 million to 1.3 billion.

Real-Time Video Generation with Pyramid Attention Broadcast
Summary: Pyramid Attention Broadcast (PAB) is introduced as a real-time, high-quality, and training-free approach for DiT-based video generation. The method is based on the observation that attention differences during the diffusion process follow a U-shaped pattern, revealing significant redundancy. To address this, PAB broadcasts attention outputs to subsequent steps in a pyramid style, applying different broadcast strategies to each attention based on their variance for optimal efficiency. Additionally, PAB incorporates broadcast sequence parallelism to enhance distributed inference efficiency. PAB outperforms baseline methods across three models, achieving real-time generation for videos up to 720p. This straightforward yet effective method is expected to serve as a strong baseline and advance future research and applications in video generation.

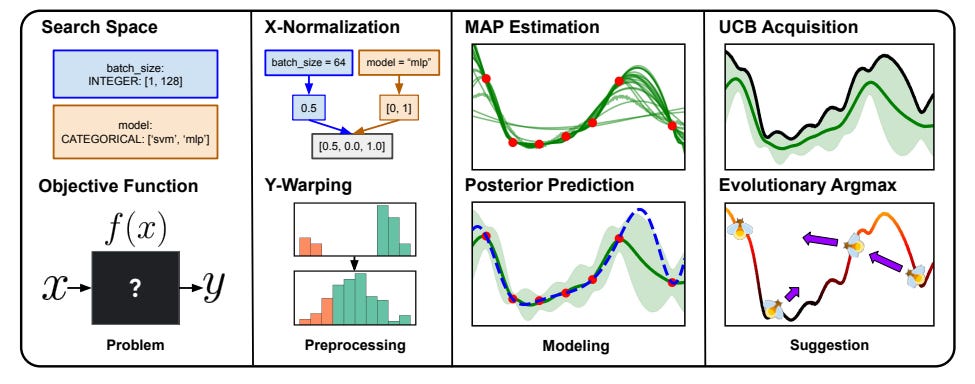
The Vizier Gaussian Process Bandit Algorithm
Summary: Google Vizier has conducted millions of optimizations, significantly accelerating research and production systems at Google, thereby showcasing the effectiveness of Bayesian optimization as a large-scale service. Over the years, the algorithm behind Vizier has undergone substantial improvements, informed by extensive research efforts and user feedback. This technical report delves into the implementation details and design choices of the current default algorithm offered by Open Source Vizier. Experimental results on standardized benchmarks highlight the algorithm's robustness and versatility, demonstrating its strong performance against well-established industry baselines across various practical scenarios.