Top AI Research Papers

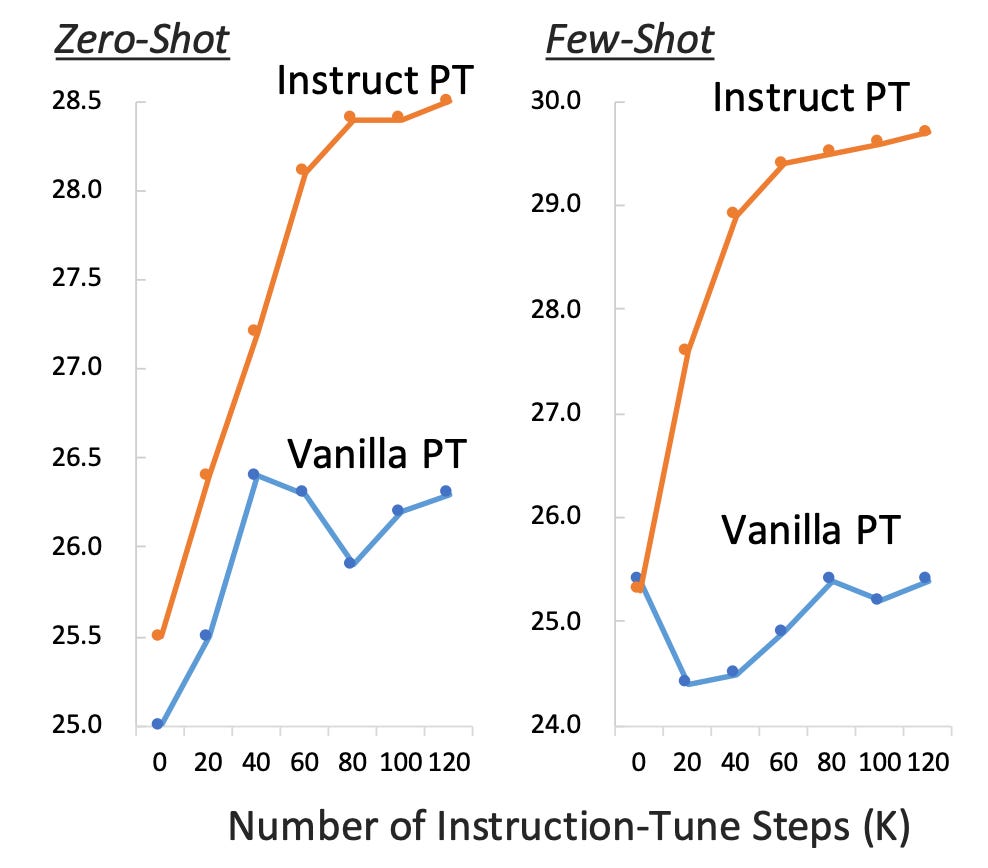
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Summary: Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. This paper explores supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In the experiments, 200M instruction-response pairs covering 40+ task categories were synthesized to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training consistently enhances pre-trained base models and benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B
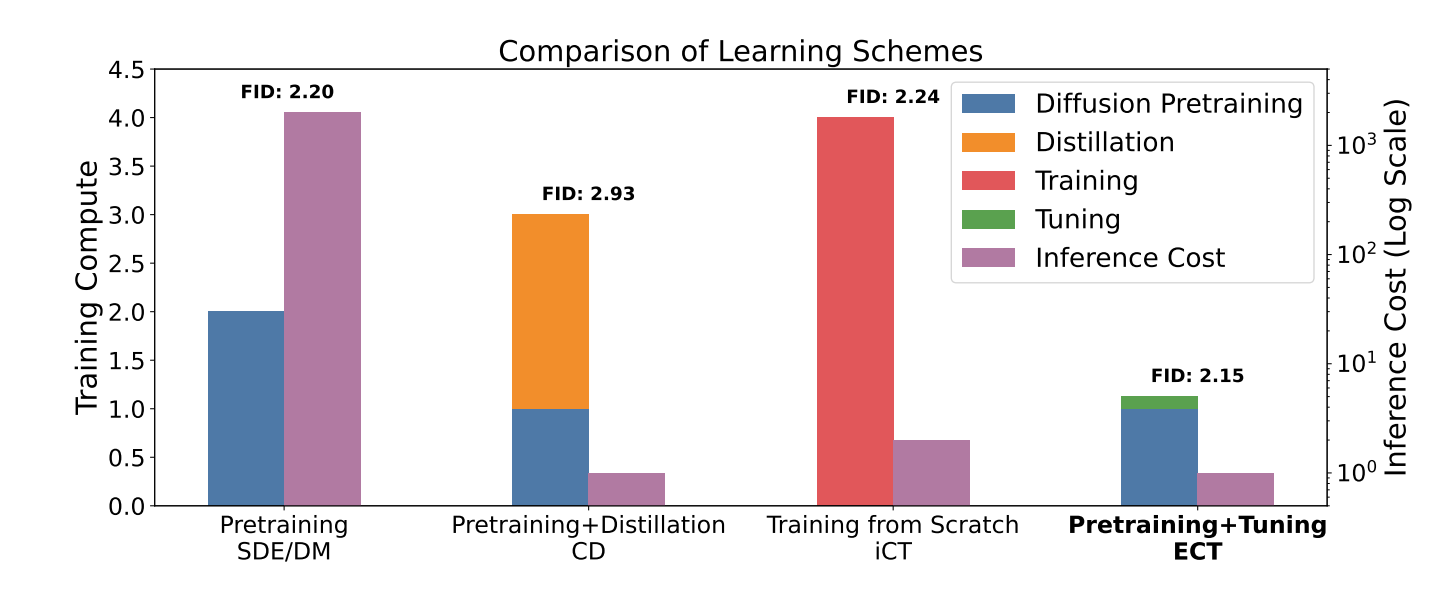
Consistency Models Made Easy
Summary: Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point, which leads to resource-intensive training. For instance, as of 2024, training a state-of-the-art CM on CIFAR-10 takes one week on 8 GPUs. This work proposes an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, it is argued that diffusion models can be viewed as a special case of CMs with a specific discretization. This allows for fine-tuning a consistency model starting from a pre-trained diffusion model and progressively approximating the full consistency condition to stronger degrees over the training process. The resulting method, termed Easy Consistency Tuning (ECT), achieves vastly improved training times while enhancing the quality of previous methods. For example, ECT achieves a 2-step FID of 2.73 on CIFAR-10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained over hundreds of GPU hours.
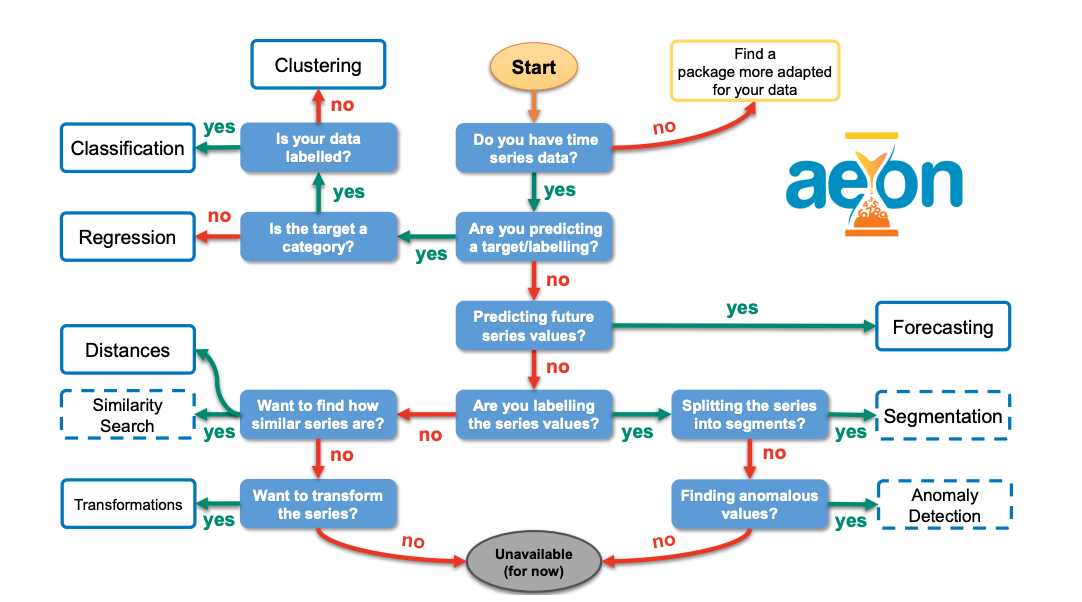
aeon: a Python toolkit for learning from time series
Summary: aeon is a unified Python 3 library designed for all machine learning tasks involving time series. The package includes modules for time series forecasting, classification, extrinsic regression, and clustering, as well as a variety of utilities, transformations, and distance measures tailored for time series data. Additionally, aeon features several experimental modules for tasks such as anomaly detection, similarity search, and segmentation. Following the scikit-learn API, aeon aims to assist new users and facilitate the integration of aeon estimators with tools like model selection and pipelines. It offers a comprehensive library of time series algorithms, including efficient implementations of the latest research advancements. By using a system of optional dependencies, aeon integrates various packages into a single interface while maintaining a core framework with minimal dependencies. The package is distributed under the 3-Clause BSD license and is available at https://github.com/aeon-toolkit/aeon.
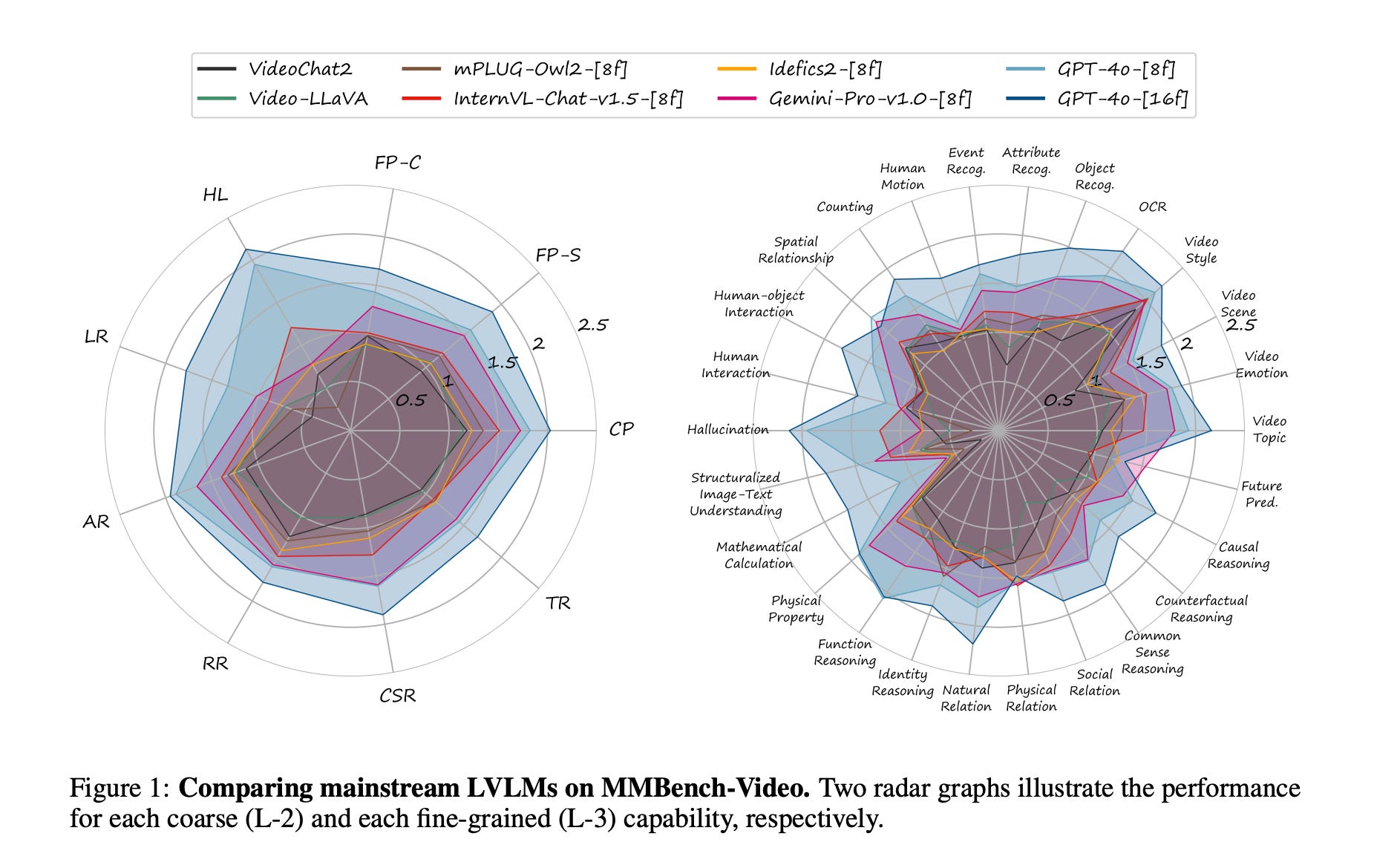
MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Summary: The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, MMBench-Video, a quantitative benchmark, has been introduced to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. GPT-4 is employed for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, comprehensive evaluations have been conducted, including both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding.
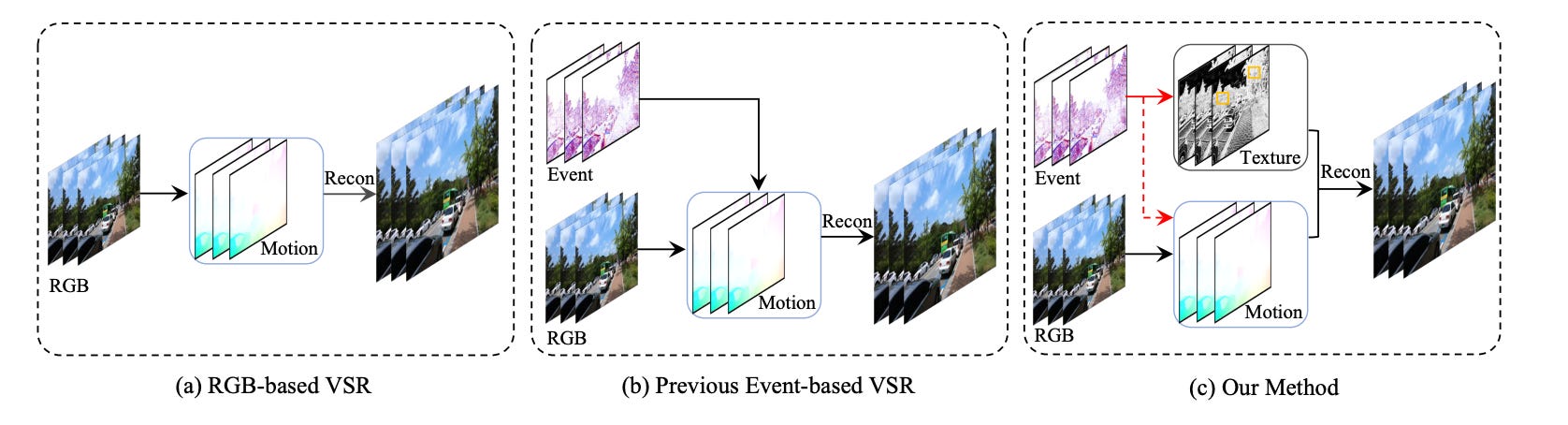
EvTexture: Event-driven Texture Enhancement for Video Super-Resolution
Summary: Event-based vision has drawn increasing attention due to its unique characteristics, such as high temporal resolution and high dynamic range. It has been used in video super-resolution (VSR) recently to enhance flow estimation and temporal alignment. Rather than using it for motion learning, this paper proposes the first VSR method that utilizes event signals for texture enhancement. The method, called EvTexture, leverages high-frequency details of events to better recover texture regions in VSR. In EvTexture, a new texture enhancement branch is introduced, along with an iterative texture enhancement module to progressively explore high-temporal-resolution event information for texture restoration. This approach allows for gradual refinement of texture regions across multiple iterations, resulting in more accurate and rich high-resolution details. Experimental results show that EvTexture achieves state-of-the-art performance on four datasets. For the Vid4 dataset, which is rich in textures, this method can achieve up to a 4.67 dB gain compared with recent event-based methods.