

Top AI Research papers

LightStereo: Channel Boost Is All You Need for Efficient 2D Cost Aggregation
Summary: Researchers have created a new stereo-matching network called LightStereo. This system is designed to be faster than previous methods. LightStereo accomplishes this by using a 3D cost volume instead of the more computationally expensive 4D costs used in conventional techniques. Prior research has explored similar approaches, but LightStereo focuses on improving the channel dimension of the 3D cost volume, where the key information for matching is located. This focus allows LightStereo to achieve high accuracy while also being efficient. The researchers compared LightStereo to existing methods and found that it performs better in terms of speed, accuracy, and resource usage. LightStereo’s analysis paves the way for the development of real-world applications that require fast and efficient stereo vision systems.

ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
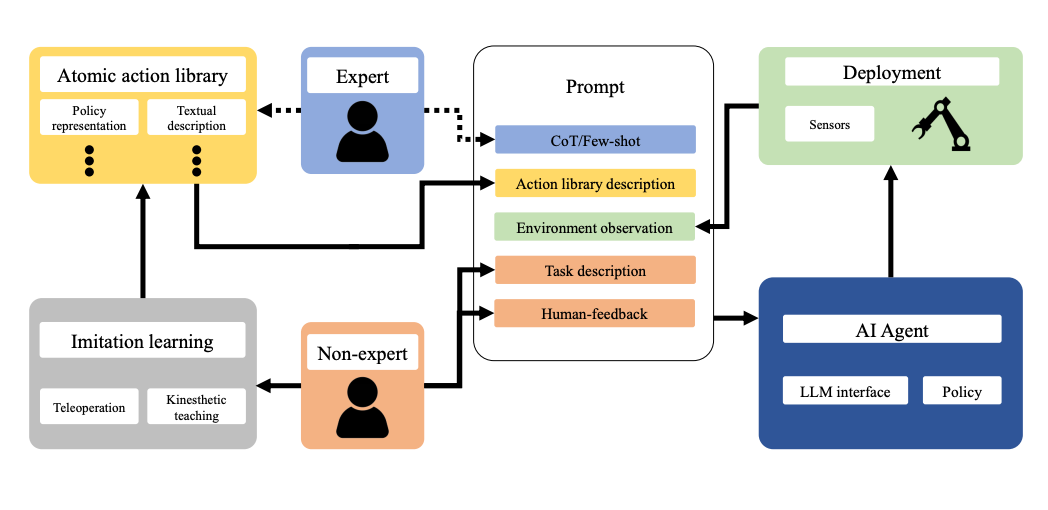
Summary: A novel framework is proposed for intuitive robot programming by non-experts. This system leverages natural language prompts and contextual information from the Robot Operating System (ROS) to bridge the gap between users and robots. Large language models (LLMs) are integrated, allowing non-experts to interact with the system through a chat interface and describe the desired tasks for the robot. An AI agent seamlessly connects ROS with a vast array of open-source and commercial LLMs. The system automatically extracts the desired behavior from the LLM output and translates it into corresponding ROS actions or services. Users can choose from three behavior modes – sequence, behavior tree, or state machine – to best suit the task. New robot actions can be readily added to the library by demonstrating them directly, facilitating continuous learning. The system incorporates human and environmental feedback to continuously improve the LLM's understanding of robot tasks.
YuLan: An Open-source Large Language Model
Summary: Researchers introduce YuLan, a series of open-source large language models (LLMs) boasting 12 billion parameters. This work aims to address the lack of training details often found in open-source LLMs, hindering further research.
YuLan's foundation is a base model pre-trained on a massive and diverse corpus of text data exceeding 1.7 trillion tokens, encompassing English, Chinese, and multilingual content. To bolster YuLan's capabilities, a three-stage pre-training approach was implemented. Subsequent training phases involve instruction-tuning and human alignment, leveraging a significant amount of high-quality synthesized data. A curriculum-learning framework was incorporated throughout the training stages. This framework allows YuLan to progressively learn complex and nuanced knowledge, starting with simpler concepts and gradually progressing to more challenging areas. YuLan's training concluded in January 2024, and it has achieved performance comparable to state-of-the-art LLMs on various English and Chinese benchmarks.

OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
Summary: A new framework called OMG-LLaVA is proposed to bridge the gap between current limitations in image and video understanding. Existing universal segmentation methods, while strong in pixel-level analysis, struggle with reasoning and responding to text instructions. Conversely, large vision-language models excel at reasoning and conversation based on visual information, but lack precise pixel-level understanding and struggle to handle visual prompts for user interaction.
OMG-LLaVA offers a comprehensive solution, combining powerful pixel-level understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Here's how it works: a universal segmentation method acts as the visual encoder, processing image information, user-defined priors, and visual prompts into visual tokens for the Large Language Model (LLM). The LLM then takes center stage, analyzing the user's text instructions and generating text responses alongside pixel-level segmentation results based on the visual data.
A key innovation is the use of perception prior embedding, which enhances the integration of user-defined priors with image features. This allows OMG-LLaVA to achieve image-level, object-level, and pixel-level reasoning and understanding within a single model. This unified approach surpasses the performance of separate specialized methods on various benchmarks. Unlike prior methods that rely on the LLM to connect individual specialists, OMG-LLaVA utilizes an efficient end-to-end training process with one encoder, one decoder, and one LLM.

Symbolic Learning Enables Self-Evolving Agents
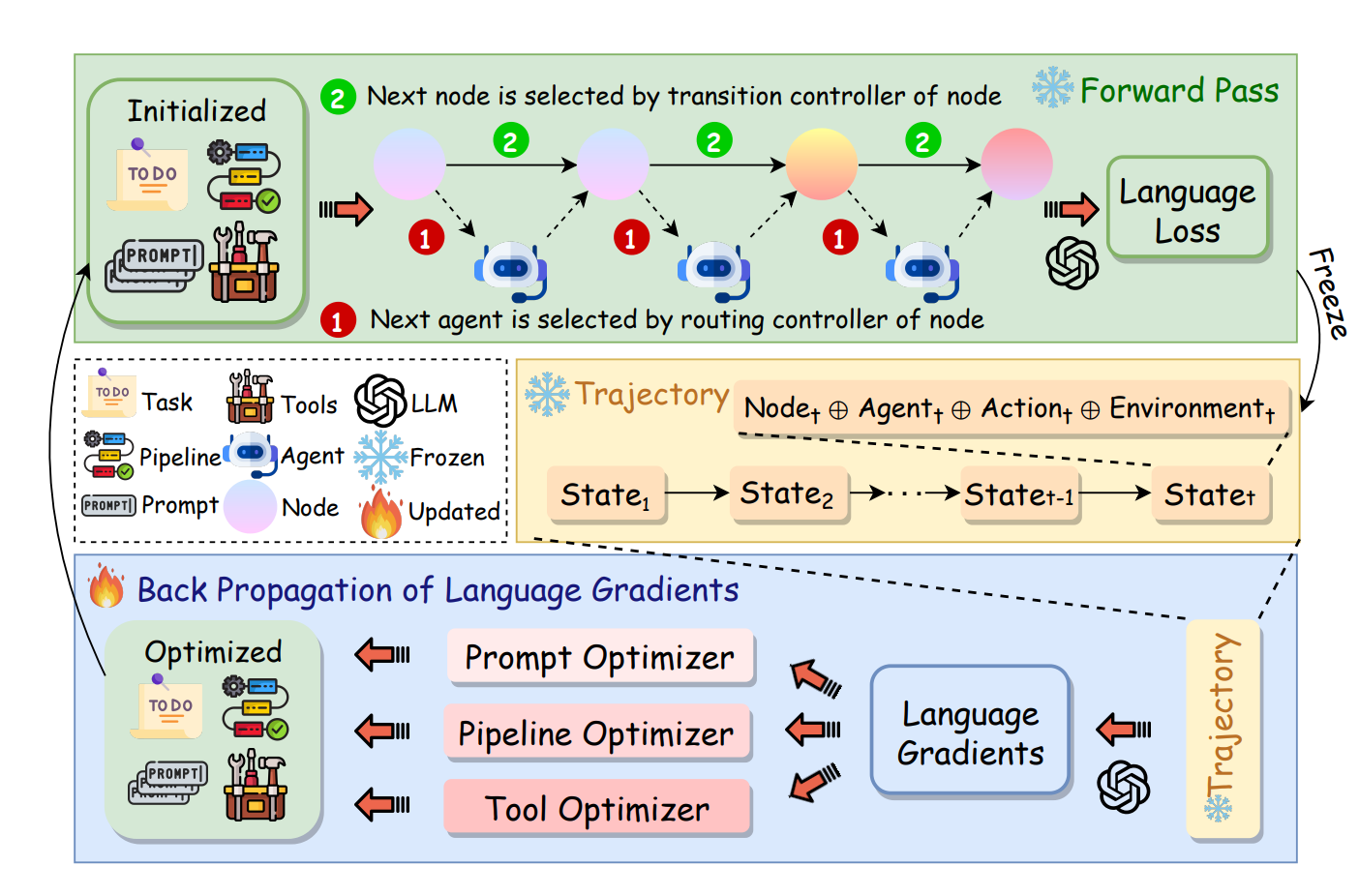
Summary: Researchers are exploring a path towards artificial general intelligence (AGI) through "language agents." These agents are complex pipelines built around large language models (LLMs) that utilize prompting techniques and various tools. While language agents have shown promise in real-world tasks, a major hurdle remains: they are currently "model-centric" or "engineering-centric." This means that advancements in prompts, tools, and pipelines heavily rely on manual engineering by human experts, rather than the agents themselves learning from data.
This paper proposes "agent symbolic learning" as a solution. This framework allows language agents to become more data-centric by enabling them to optimize themselves autonomously. It views language agents as symbolic networks, where learnable elements are defined by prompts, tools, and their configuration. Agent symbolic learning mimics back-propagation and gradient descent, fundamental algorithms in connectionist learning, but instead of numeric weights, it utilizes natural language representations of weights, loss, and gradients.
AI Image of the Day
Prompt: Cats driving Ice Cream Truck
Tool: https://perchance.org

OMG-LLaVA, as an advanced AI image understanding and reasoning technology, offers users a flexible interactive experience with its multi-level image comprehension capabilities, universal segmentation methods, and perceptual prior embedding modules. Whether you are an image recognition expert, a natural language processing researcher, or a practitioner in multi-level image understanding tasks, OMG-LLaVA can bring you a brand new experience.