Top AI Research Papers

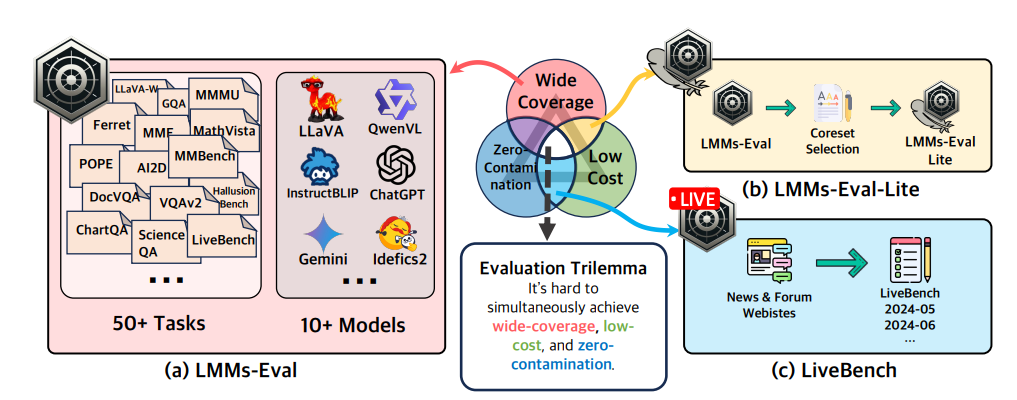
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Summary: The advances in large foundation models necessitate benchmarks that are wide in coverage, low in cost, and free from contamination. Despite ongoing exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited. To address this gap, LMMS-EVAL is introduced—a unified and standardized multimodal benchmark framework encompassing over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. However, while LMMS-EVAL offers comprehensive coverage, it falls short in achieving low cost and zero contamination. To address this evaluation dilemma, LMMS-EVAL LITE is introduced—a pruned evaluation toolkit that emphasizes both coverage and efficiency. Additionally, Multimodal LIVEBENCH is presented utilizing continuously updating news and online forums to assess models' generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach.
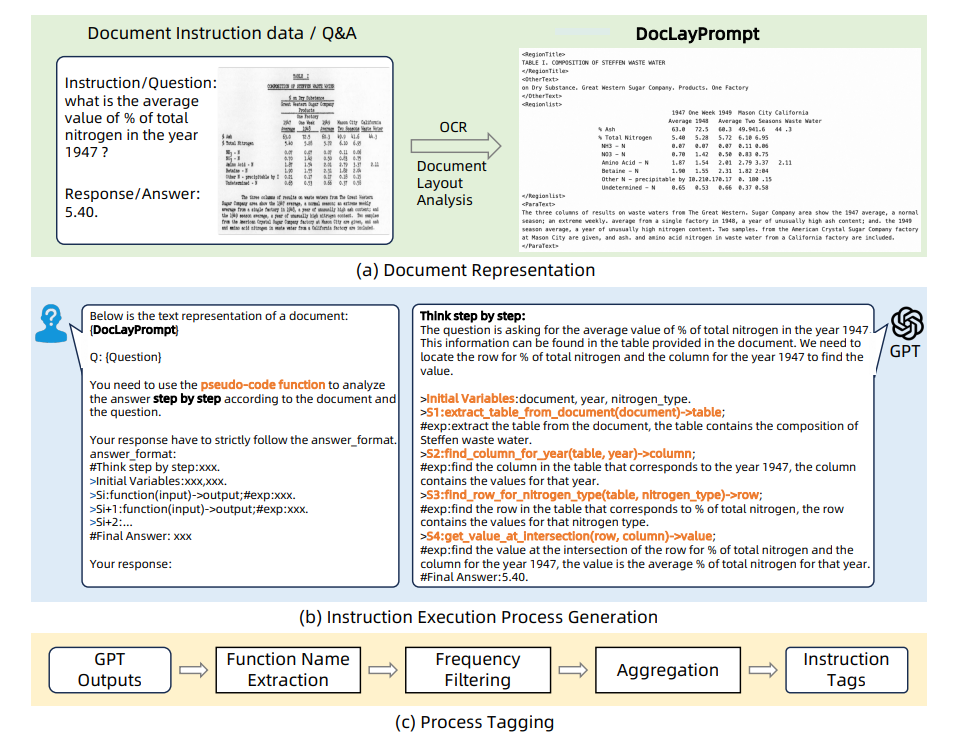
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Summary: Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on the document visual question answering (VQA) task, particularly after being trained on document instruction datasets. An effective evaluation method for document instruction data is crucial for constructing instruction data with high efficacy, which in turn facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, hindering the effective assessment of document instruction datasets and constraining their construction.
In this paper, a new approach called ProcTag is proposed, which is a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, a novel semi-structured layout-aware document prompting strategy called DocLayPrompt is proposed for effectively representing documents.
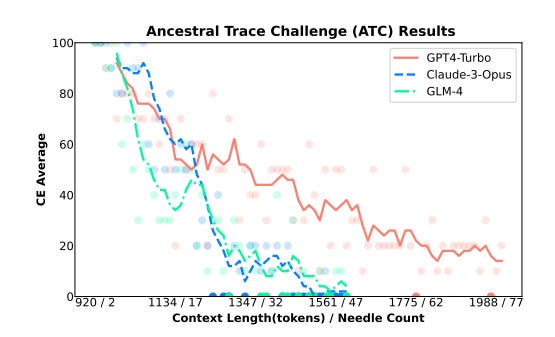
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
Summary: In evaluating the long-context capabilities of large language models (LLMs), identifying content relevant to a user's query from original long documents is a crucial prerequisite for any LLM to answer questions based on long text. NeedleBench, a newly presented framework, consists of a series of progressively more challenging tasks for assessing bilingual long-context capabilities. These tasks span multiple length intervals (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different depth ranges, allowing the strategic insertion of critical data points in different text depth zones to rigorously test the retrieval and reasoning capabilities of models in diverse contexts.
NeedleBench is used to assess how well the leading open-source models can identify key information relevant to the question and apply that information to reasoning in bilingual long texts. Furthermore, the Ancestral Trace Challenge (ATC) is proposed to mimic the complexity of logical reasoning challenges likely to be present in real-world long-context tasks, providing a simple method for evaluating LLMs in dealing with complex long-context situations.
The results suggest that current LLMs have significant room for improvement in practical long-context applications, as they struggle with the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks.
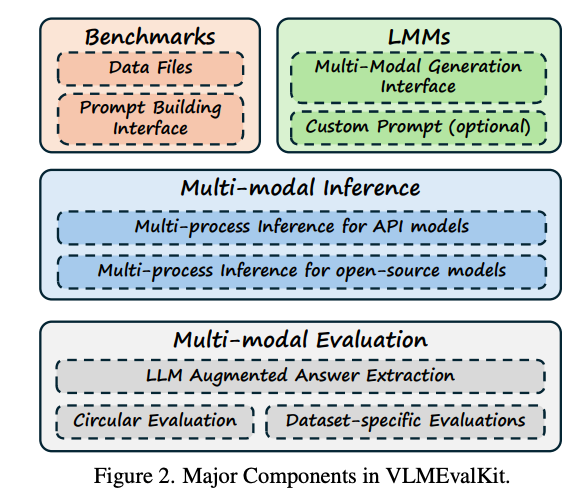
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models
Summary: VLMEvalKit is an open-source toolkit designed for evaluating large multi-modality models based on PyTorch. This toolkit aims to provide a user-friendly and comprehensive framework for researchers and developers to evaluate existing multi-modality models and publish reproducible evaluation results. VLMEvalKit implements over 70 different large multi-modality models, including both proprietary APIs and open-source models, and supports more than 20 different multi-modal benchmarks.
A single interface allows new models to be easily added to the toolkit, while it automatically handles the remaining workloads, including data preparation, distributed inference, prediction post-processing, and metric calculation. Although VLMEvalKit is currently used mainly for evaluating large vision-language models, its design is compatible with future updates that incorporate additional modalities, such as audio and video.
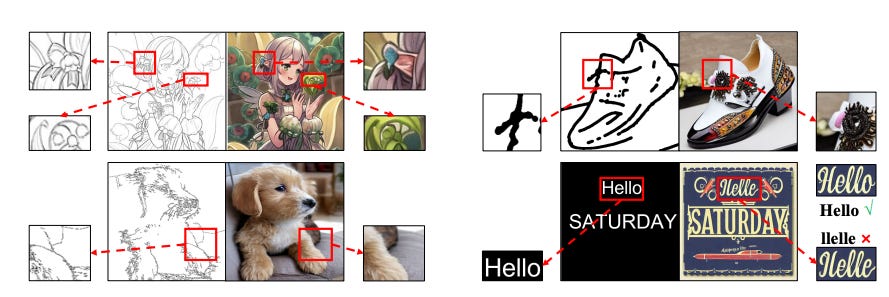
How Control Information Influences Multilingual Text Image Generation and Editing?
Summary: Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily utilize a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, this research investigates its influence from three perspectives: input encoding, its role at different stages, and output features.
The findings reveal that: Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps.Control information plays distinct roles at different stages of the de-noising process.Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, a novel framework called TextGen is proposed to enhance generation quality by optimizing control information. This framework improves input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, a two-stage generation framework is employed to align the different roles of control information at different stages. Furthermore, an effective and lightweight dataset for training is introduced.
TextGen achieves state-of-the-art performance in both Chinese and English text generation.