Top AI Research papers (Last week)
Top AI Research papers (Last week)
June 3 - June 9

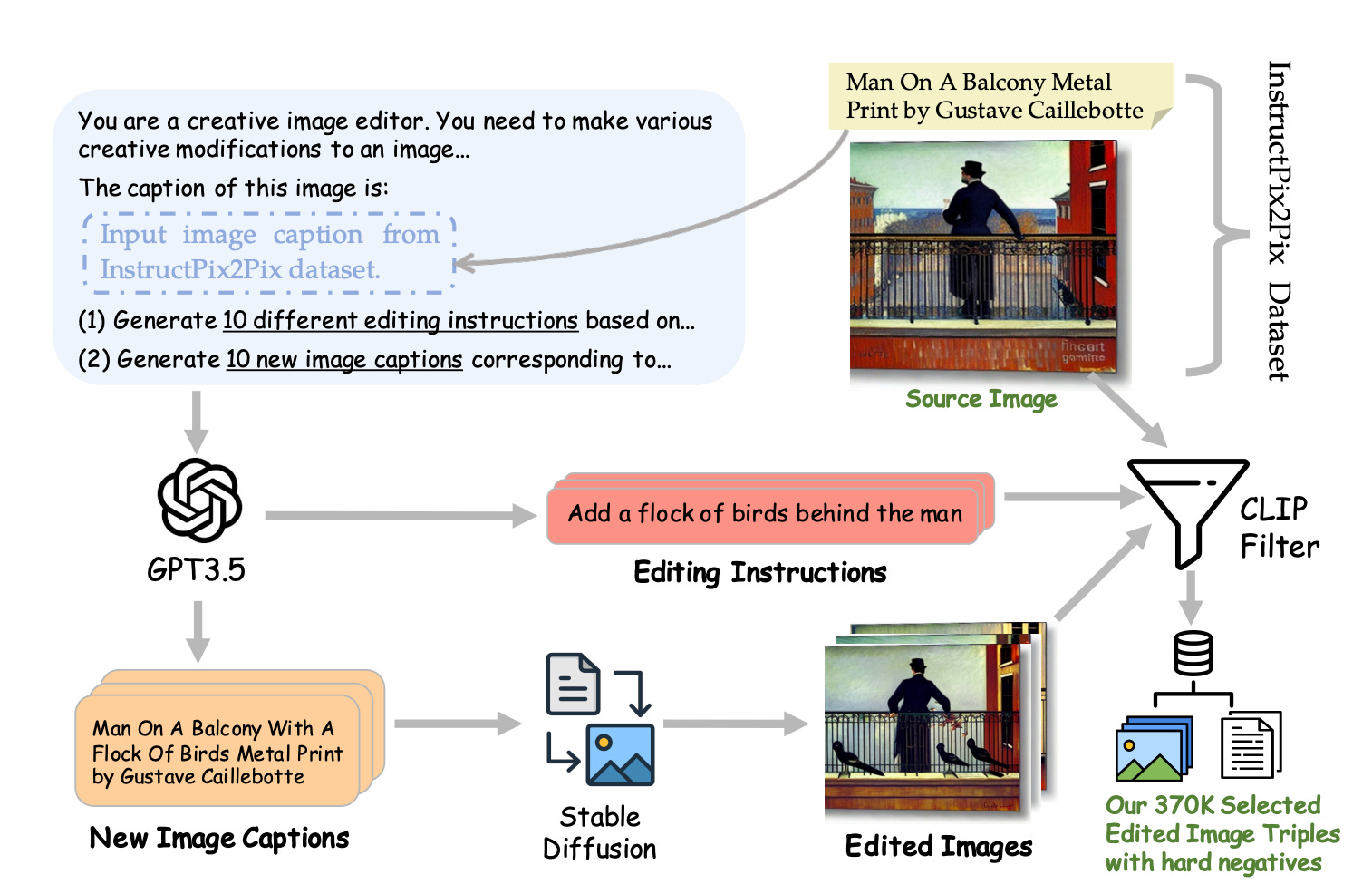
Differentiable Time-Varying Linear Prediction in the Context of End-to-End Analysis-by-Synthesis
Summary: Because of its intrinsic recursive structure, modern deep learning frameworks have difficulty efficiently training the linear prediction (LP) operator for audio synthesis. Frame-wise approximations, a typical acceleration approach, do not apply well to test-time circumstances in which the LP is computed on a sample-by-sample basis. This study tackles this issue by offering an efficient, differentiable, and sample-wise LP formulation that is appropriate for end-to-end training.
The authors use the efficient time-invariant LP implementation from the GOLF vocoder to handle time-varying signals. By adding this technique into the standard source-filter model, they show that the upgraded GOLF architecture outperforms its frame-wise competitors in terms of LP coefficient learning and speech reconstruction.
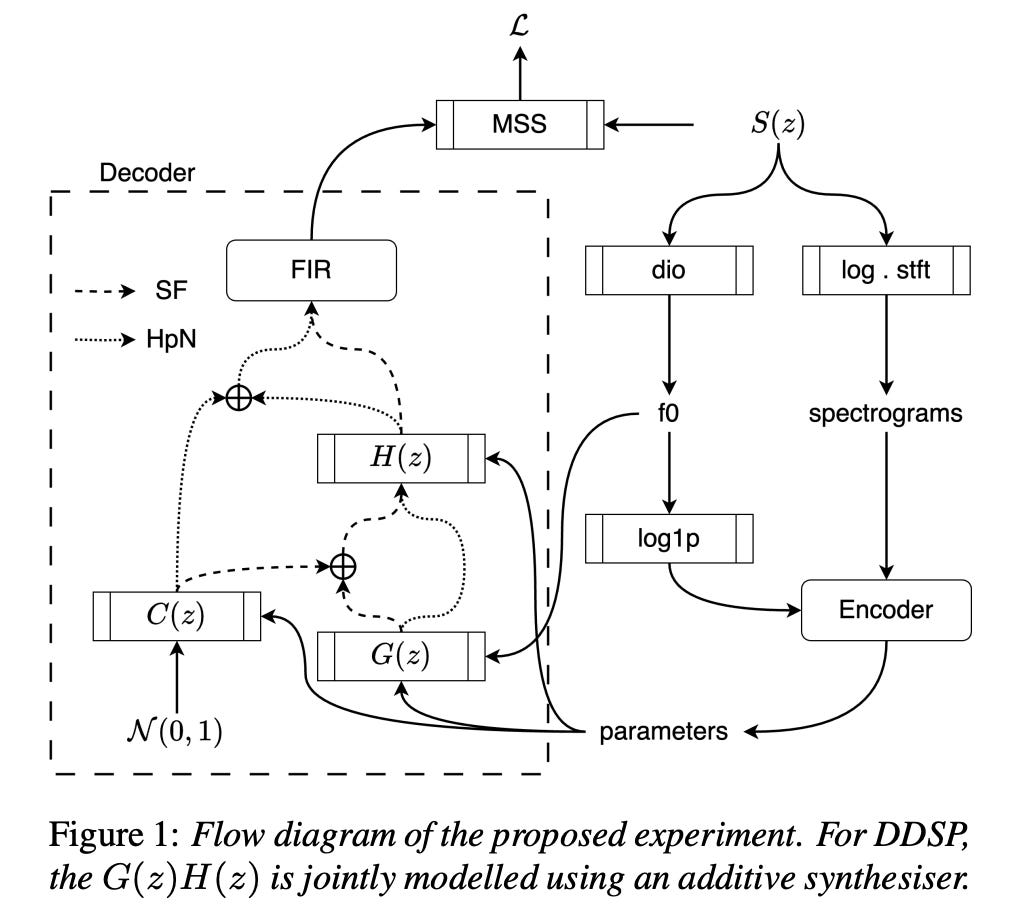
LAWGPT: A Chinese Legal Knowledge-Enhanced Large Language Model
Summary: Researchers have demonstrated that large language models (LLMs), both private and open-source, can perform a wide range of jobs. These models, however, fall short when applied to real-world legal activities in China. Proprietary models pose worries about data privacy in delicate legal matters, but open-source models lack the requisite legal understanding to perform effectively. To fill this void, LAWGPT is offered as the first open-source model tailored exclusively for Chinese legal applications. LAWGPT combines two main components: legal-oriented pre-training and legal-supervised fine-tuning. During legal-oriented pre-training, the model is trained on a large dataset of Chinese law texts to gain legal domain knowledge. To improve performance on specific legal tasks, a knowledge-driven instruction dataset is used for legal supervised fine-tuning.
AGENTGYM: Evolving Large Language Model-based Agents across Diverse Environments
Summary: Building generalist agents capable of managing a variety of jobs and adapting to changing settings has long been a goal in AI. Large language models (LLMs) are regarded as a potential basis because of their adaptability. Current techniques have drawbacks. Some need humans to create step-by-step instructions for AI to follow, restricting scalability and exploration. Others allow for independent learning in confined situations, resulting in specialist agents with limited skill sets.
This study takes an important step toward generalist LLM agents with self-evolution. The authors provide a three-part approach: various habitats for exploration and learning, a curated set of example actions to teach agents fundamental abilities, and a scalable technique for self-evolution.
AGENTGYM, a revolutionary framework, is used to do this. It provides a range of landscapes and tasks that are designed for broad exploration in real time, using a consistent structure and allowing several agents to explore simultaneously. Furthermore, AGENTGYM includes a comprehensive library of explicit instructions, a benchmark suite, and high-quality trajectories across settings.
BitsFusion: 1.99 bits Weight Quantization of Diffusion Model
Summary: Diffusion-based image generation models have become incredibly successful at creating high-quality content. However, their massive number of parameters translates to large file sizes, hindering storage, transfer, and deployment on resource-constrained devices. This work proposes a novel weight quantization method specifically targeting the UNet architecture within Stable Diffusion v1.5. The goal is to achieve a significantly smaller model size while maintaining or even improving generation quality. Through several innovative techniques, the quantized model boasts a remarkable 7.9 times reduction in size compared to the original. These techniques include:
Optimal bit allocation: Each layer within the model is assigned the most suitable number of bits (as low as 1.99 bits in some cases) for efficient storage.
Quantization-aware initialization: The quantized model is initialized in a way that optimizes its performance after quantization.
Enhanced training strategy: A custom-designed training strategy significantly reduces errors introduced during the quantization process.
The paper further demonstrates the quantized model's superior generation quality through extensive evaluations using benchmark datasets and human studies.

VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Summary: The growing popularity of multi-modal retrieval tasks has exposed limitations in existing retrieval methods. These methods are primarily text-focused, neglecting valuable visual information. Even vision-language models like CLIP struggle to effectively represent purely textual or visual data.
This work proposes VISTA, a novel embedding model designed for universal multi-modal retrieval. VISTA boasts three key technical contributions. First, it introduces a flexible architecture that empowers a powerful text encoder with visual understanding capabilities through the incorporation of visual token embeddings. Second, the work outlines two innovative data generation strategies that produce high-quality composed image-text data, crucial for training the embedding model. Finally, VISTA leverages a multi-stage training algorithm. This algorithm first aligns the visual token embedding with the text encoder using a large collection of weakly labeled data. Subsequently, it refines the multi-modal representation capability using the generated composed image-text data. Experiments demonstrate that VISTA achieves superior performance across various multi-modal retrieval tasks, excelling in both zero-shot and supervised settings.