

Top AI Research Papers -Last week
Top AI Research Papers -Last week
September 1 - September 8, 2024

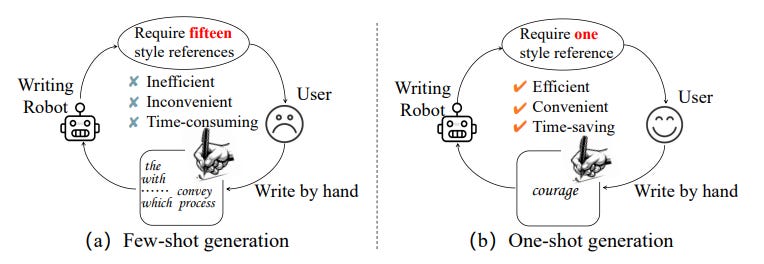
One-Shot Diffusion Mimicker for Handwritten Text Generation
Summary: Existing methods for handwritten text generation typically require more than ten handwriting samples as style references. However, in practical applications, users generally prefer a handwriting generation model that operates with only a single reference sample for greater convenience and efficiency. This approach, referred to as "one-shot generation," simplifies the process but presents a significant challenge due to the difficulty of accurately capturing a writer's style from just one sample, particularly when extracting fine details from the characters' edges amidst sparse foreground and unwanted background noise. To address this issue, a One-shot Diffusion Mimicker (One-DM) is proposed to generate handwritten text that mimics any calligraphic style using only a single reference sample.
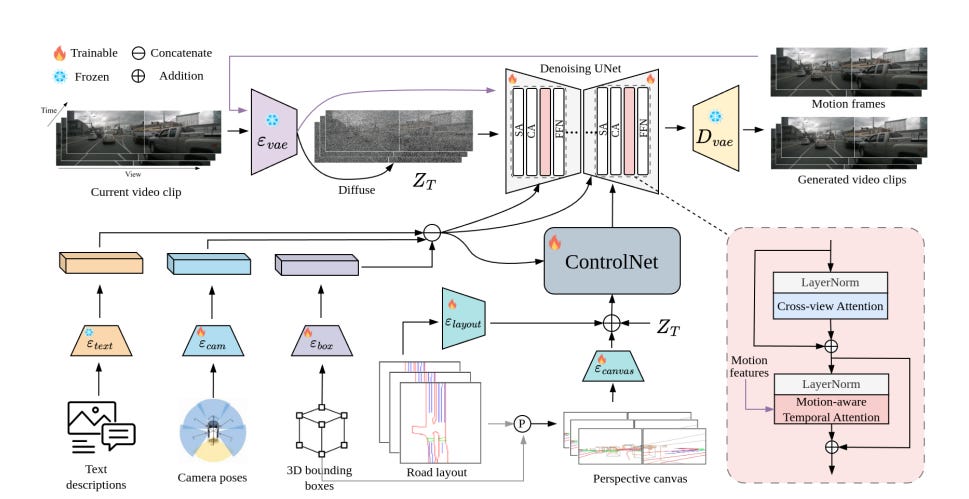
DreamForge: Motion-Aware Autoregressive Video Generation for Multi-View Driving Scenes
Summary: Recent advances in diffusion models have greatly improved the controllable generation of streetscapes and have facilitated downstream perception and planning tasks. However, challenges remain in maintaining temporal coherence, generating long videos, and accurately modeling driving scenes. To address these issues, DreamForge is introduced as an advanced diffusion-based autoregressive video generation model designed for the long-term generation of 3D-controllable and extensible video. In terms of controllability, DreamForge supports flexible conditions such as text descriptions, camera poses, 3D bounding boxes, and road layouts, while also providing perspective guidance to ensure the generation of driving scenes that are both geometrically and contextually accurate. To enhance consistency, the model incorporates inter-view consistency through cross-view attention and maintains temporal coherence via an autoregressive architecture enhanced with motion cues.
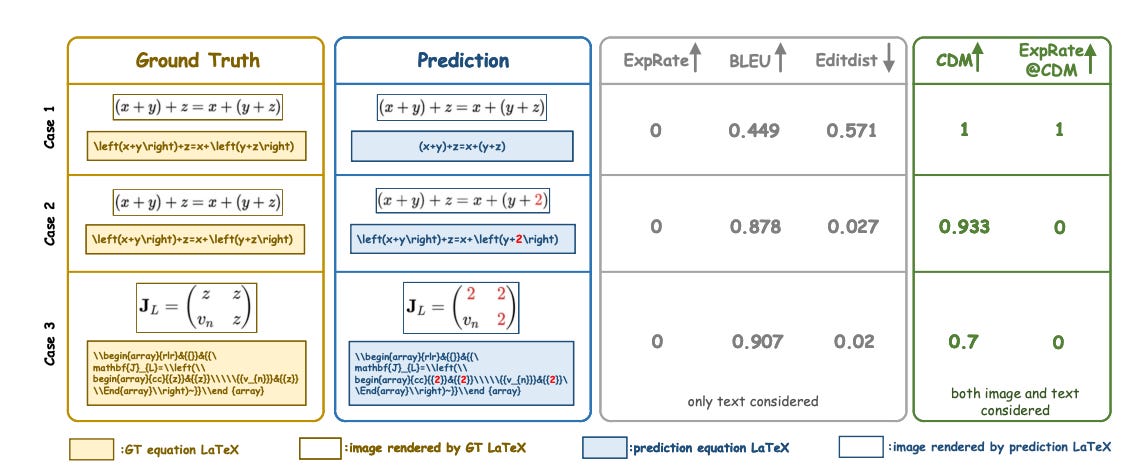
CDM: A Reliable Metric for Fair and Accurate Formula Recognition Evaluation
Summary: Formula recognition poses significant challenges due to the complex structure and varied notation of mathematical expressions. Despite ongoing advancements in formula recognition models, the evaluation metrics commonly used, such as BLEU and Edit Distance, still present notable limitations. These metrics fail to account for the fact that a single formula can have multiple valid representations and are highly sensitive to the distribution of training data, leading to potential unfairness in evaluation. To address this issue, a Character Detection Matching (CDM) metric is proposed to ensure more objective evaluation by introducing an image-level, rather than LaTeX-level, metric score. Specifically, CDM converts both the model-predicted LaTeX and the ground-truth LaTeX formulas into image-formatted versions, then applies visual feature extraction and localization techniques for precise character-level matching that includes spatial position information.
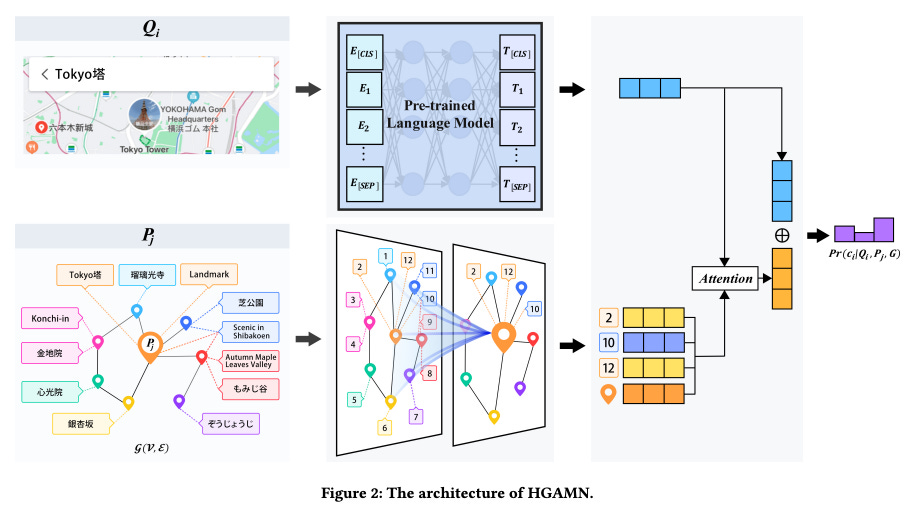
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
Summary: The growing interest in international travel has led to an increased demand for retrieving points of interest (POIs) in multiple languages. This is especially valuable for locating local venues, such as restaurants and scenic spots, in unfamiliar languages while traveling abroad. Multilingual POI retrieval, which enables users to find desired POIs in a preferred language using queries in various languages, has become a crucial feature of modern global map applications like Baidu Maps. However, this task is challenging due to two primary issues: (1) visiting sparsity and (2) multilingual query-POI matching. To address these challenges, a Heterogeneous Graph Attention Matching Network (HGAMN) is proposed. Specifically, a heterogeneous graph is constructed with two types of nodes—POI nodes and query nodes—using the search logs from Baidu Maps. To tackle the issue of visiting sparsity, edges are created between different POI nodes to link low-frequency POIs with high-frequency ones, facilitating the transfer of knowledge from frequently visited POIs to those visited less often. To address the challenge of multilingual query-POI matching, edges are formed between POI and query nodes based on co-occurrences between queries and POIs, allowing queries in different languages and formulations to be aggregated for individual POIs.
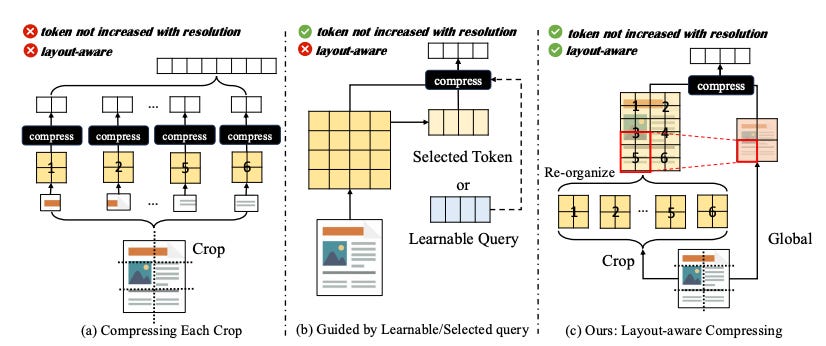
mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
Summary: Multimodal Large Language Models (MLLMs) have shown promising OCR-free document understanding capabilities by increasing the supported resolution of document images. However, this improvement comes at a cost: generating thousands of visual tokens for a single document image, resulting in excessive GPU memory usage and slower inference times, particularly in multi-page document comprehension. To address these challenges, this work proposes a High-resolution DocCompressor module, which compresses each high-resolution document image into 324 tokens, guided by low-resolution global visual features. With this compression in place, the DocOwl2 model is developed to enhance multi-page document comprehension while balancing token efficiency and question-answering performance. DocOwl2 is trained under a three-stage framework: Single-image Pre-training, Multi-image Continue-pretraining, and Multi-task Finetuning. It sets a new state-of-the-art across multi-page document understanding benchmarks, reducing first-token latency by over 50%, and demonstrates advanced capabilities in multi-page question answering, providing explanations with evidence pages, and understanding cross-page structures. Additionally, compared to single-image MLLMs trained on similar data, DocOwl2 achieves comparable single-page understanding performance with fewer than 20% of the visual tokens.
As we close out this edition of our AI newsletter, I want to thank you, our community of Spartans for your ongoing curiosity and commitment.
Until next time -stay curious and happy learning!