Top AI Research Papers - Last Week
Top AI Research Papers - Last Week
July 20 - July 28, 2024

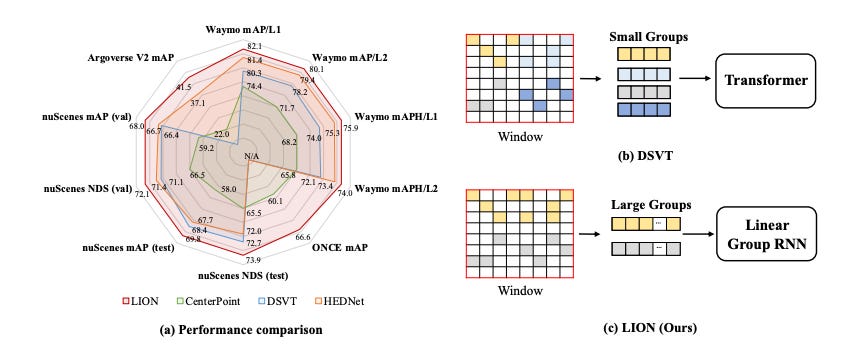
LION: Linear Group RNN for 3D Object Detection in Point Clouds
Summary: The benefit of transformers in large-scale 3D point cloud perception tasks, such as 3D object detection, is limited by their quadratic computation cost when modeling long-range relationships. In contrast, linear RNNs have low computational complexity and are suitable for long-range modeling. Toward this goal, a simple and effective window-based framework built on Linear grOup RNN (i.e., performing linear RNN for grouped features) for accurate 3D object detection, called LION, is proposed. The key property is to allow sufficient feature interaction in a much larger group than transformer-based methods. However, effectively applying linear group RNN to 3D object detection in highly sparse point clouds is not trivial due to its limitation in handling spatial modeling. To tackle this problem, a 3D spatial feature descriptor is introduced and integrated into the linear group RNN operators to enhance their spatial features rather than blindly increasing the number of scanning orders for voxel features. Furthermore, it is worth mentioning that LION-Mamba achieves state-of-the-art results on the Waymo, nuScenes, Argoverse V2, and ONCE datasets.
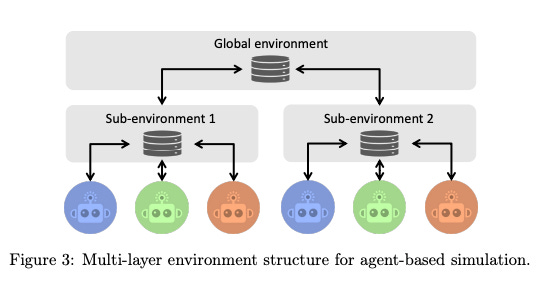
Very Large-Scale Multi-Agent Simulation in AgentScope
Summary: Recent advances in large language models (LLMs) have opened new avenues for applying multi-agent systems in very large-scale simulations. However, existing platforms face challenges such as limited scalability, low efficiency, unsatisfied agent diversity, and effort-intensive management processes. To address these challenges, several new features and components for AgentScope, a user-friendly multi-agent platform, are developed, enhancing its convenience and flexibility for supporting large-scale simulations. An actor-based distributed mechanism is proposed as the underlying technological infrastructure for great scalability and high efficiency. Flexible environment support is provided for simulating various real-world scenarios, enabling parallel execution of multiple agents, centralized workflow orchestration, and both inter-agent and agent-environment interactions. These improvements make AgentScope a robust solution for conducting extensive and efficient multi-agent simulations.
Harnessing Temporal Causality for Advanced Temporal Action Detection
Summary: As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling in TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, a new approach is proposed that leverages the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. This approach introduces CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. CausalTAD effectively captures the causal relationships in actions, providing a more accurate temporal action detection framework. The novel combination of causal attention and causal Mamba significantly improves the precision and reliability of action boundary detection, setting a new standard in the field. Extensive experiments demonstrate the superiority of CausalTAD over existing methods, validating its effectiveness in real-world scenarios.
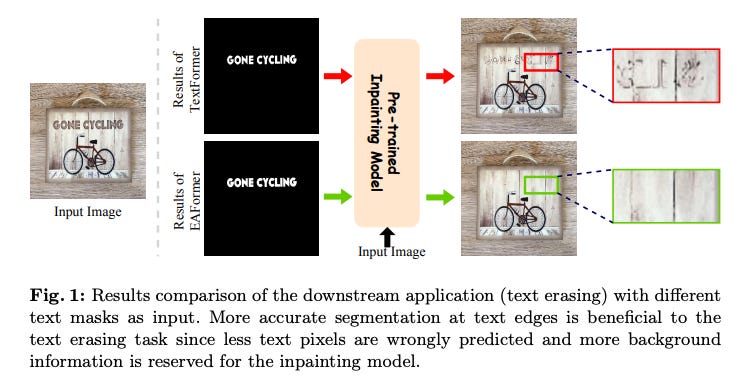
EAFormer: Scene Text Segmentation with Edge-Aware Transformers
Summary: Scene text segmentation aims at cropping texts from scene images, often to assist generative models in editing or removing texts. Existing text segmentation methods tend to involve various text-related supervisions for better performance. However, most of them overlook the importance of text edges, which are significant for downstream applications. In this paper, Edge-Aware Transformers (EAFormer) are proposed to segment texts more accurately, especially at the edges. Specifically, a text edge extractor is designed to detect edges and filter out edges of non-text areas. An edge-guided encoder is then proposed to make the model focus more on text edges. Finally, an MLP-based decoder is employed to predict text masks. Extensive experiments on commonly-used benchmarks verify the effectiveness of EAFormer. This approach enhances text segmentation accuracy by emphasizing edge detection and focusing on text boundaries, improving performance in real-world applications.
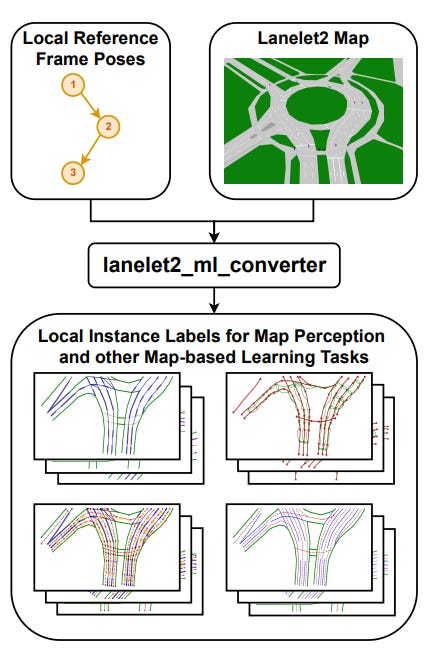
Generation of Training Data from HD Maps in the Lanelet2 Framework
Summary: Using HD maps directly as training data for machine learning tasks has seen a surge in popularity and shown promising results, especially in map perception. However, a standardized HD map framework supporting all aspects of map-based automated driving and training label generation from map data does not exist. Additionally, feeding map perception models with map data as part of the input during real-time inference is not adequately addressed by the research community. To fill this gap, we present lanelet2_ml_converter, an integrated extension to the HD map framework Lanelet2, which is widely used in automated driving systems by academia and industry. This addition enables Lanelet2 to unify map-based automated driving, machine learning inference, and training, all from a single source of map data and format. Requirements for a unified framework are analyzed, and the implementation of these requirements is described. This integration simplifies the process of utilizing HD maps for both training and inference in automated driving systems, promoting consistency and efficiency in developing map-based applications.