

Top AI Research Papers(Last week)
Top AI Research Papers(Last week)
May 27 - June 3, 2024

MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
Summary: While raw video provides a lot of face expression characteristics for portrait animation, its application has been limited owing to issues such as unintentional identity transfer and backdrop distractions. To tackle these challenges, researchers created MegActor, a revolutionary technique that uses a conditional diffusion model. MegActor addresses these challenges by producing training data with constant movements but varied identities, isolating and encoding background information, and using style transfer to replicate the look of the reference image. Notably, MegActor produces amazing results with using publicly available data, making it an important tool for the open-source animation community.

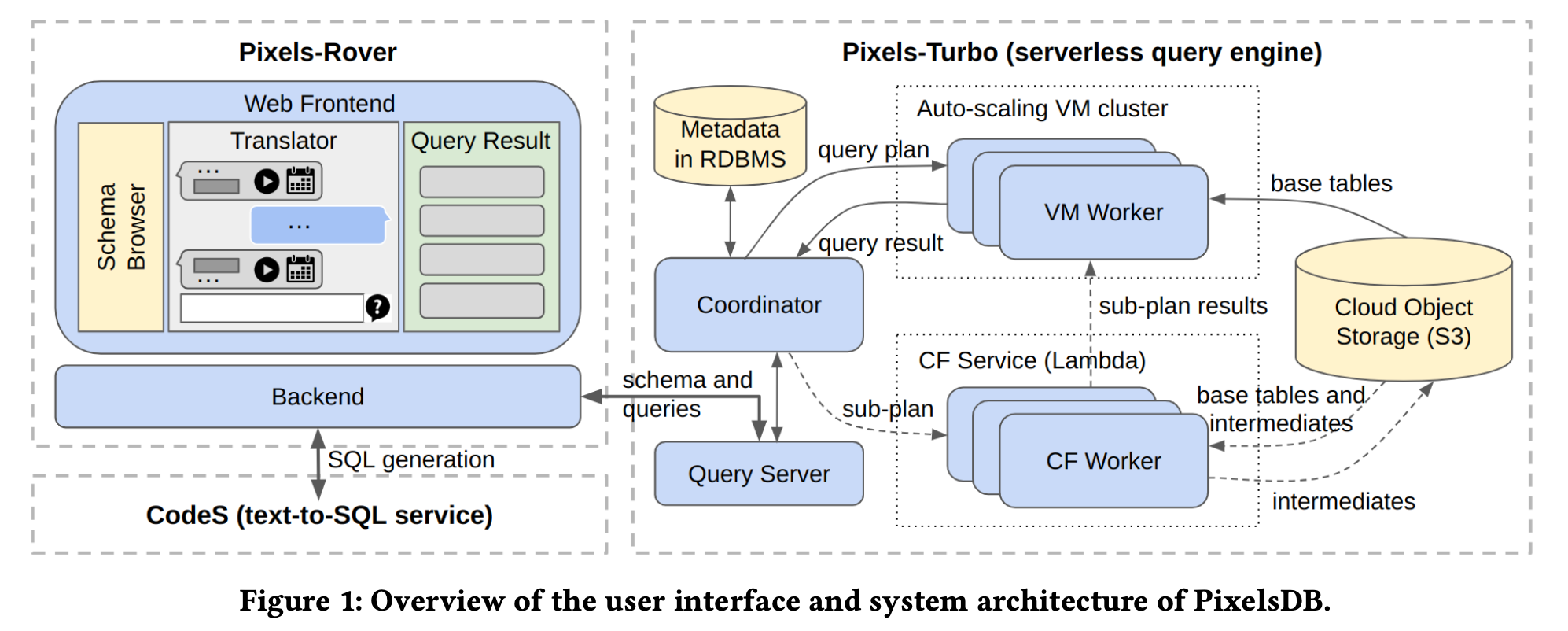
PixelsDB: Serverless and Natural-Language-Aided Data Analytics with Flexible Service Levels and Prices
Summary: Researchers are investigating how to make data analysis more accessible to non-experts. While serverless query processing provides benefits such as automated administration and variable pricing, creating sophisticated SQL queries and selecting the appropriate engine remain challenges. This study introduces PixelsDB, an open-source system that aims to overcome this gap. PixelsDB provides users with a natural language interface driven by powerful language models, enabling them to construct and debug SQL queries without the need for extensive technical knowledge. Furthermore, PixelsDB uses a serverless design with varying service levels based on query urgency. This implies that consumers may select between speedier processing at greater prices for urgent inquiries and slower, more cost-effective solutions for less pressing activities.
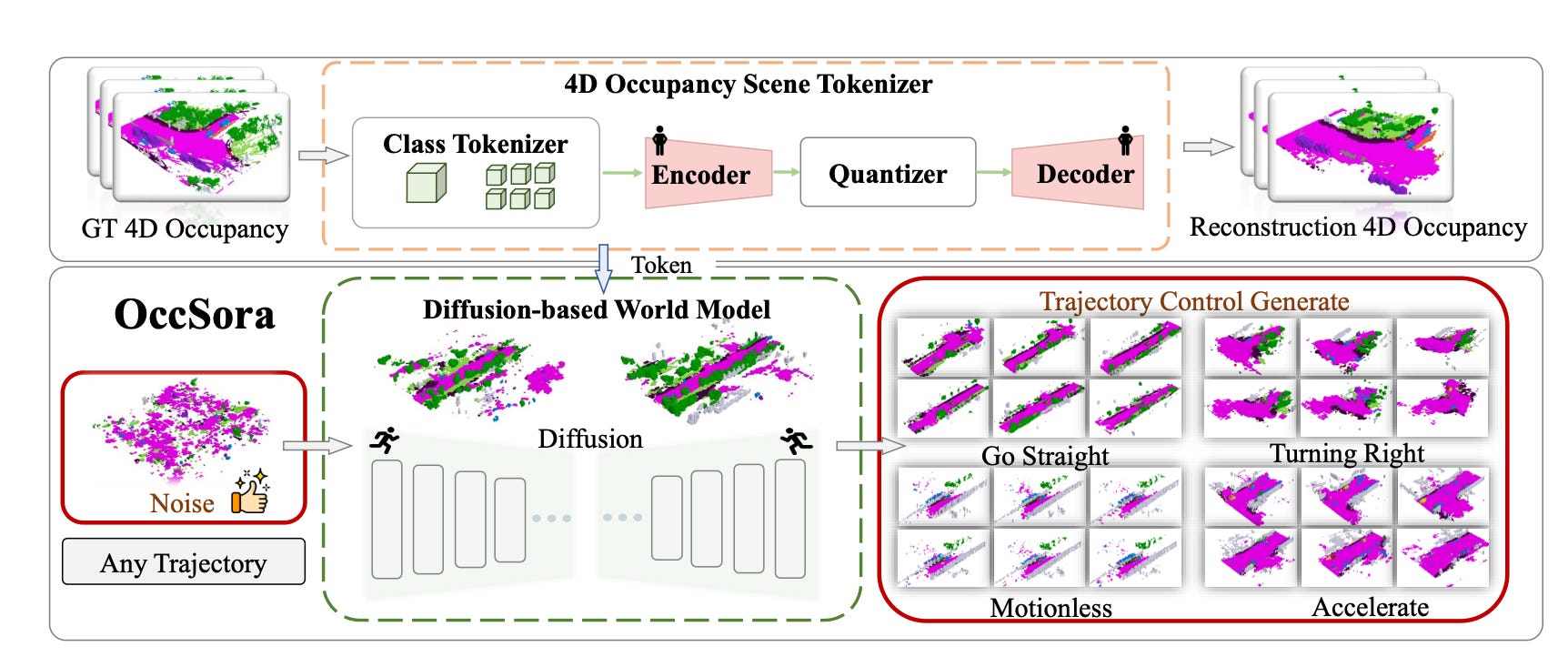
OccSora: 4D Occupancy Generation Models as World Simulators for Autonomous Driving
Summary: Researchers are researching new approaches to help autonomous cars analyze and anticipate the evolution of 3D scenes. Traditional methods centered on tracking the movement of single items. A recent technique, known as a world model, offers a more thorough framework for analyzing overall scene dynamics.
One shortcoming of present world models is their reliance on autoregressive approaches for predicting future states, which proves inefficient for long-term forecasting.To solve this, researchers introduced OccSora, a new diffusion-based model for creating 4D occupancy grids that depict the presence or absence of objects in a 3D region across time. OccSora is evaluated using a widely used dataset and proves its capacity to make 16-second films with realistic 3D layouts and seamless frame transitions. This result demonstrates the ability to capture the spatial and temporal dynamics of driving scenarios. Furthermore, the model's capacity to take into account a planned trajectory implies that it has the potential to serve as a world simulator for influencing autonomous vehicle decisions.
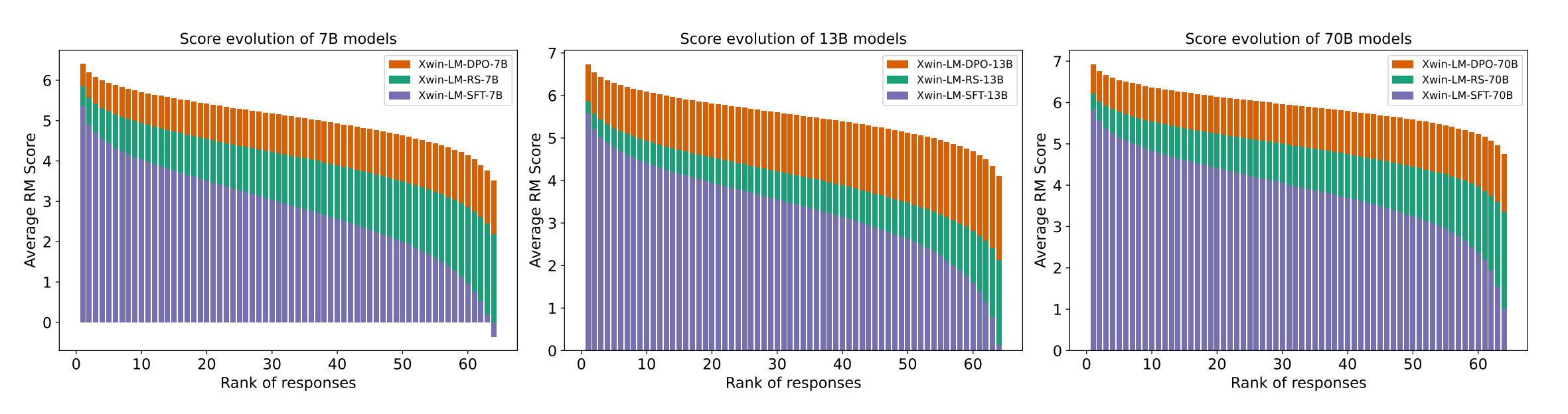
Xwin-LM: Strong and Scalable Alignment Practice for LLMs
Summary: A new approach to aligning large language models (LLMs) is presented in this research, called Xwin-LM. This approach is a comprehensive suite of techniques designed to improve the alignment of LLMs with desired behaviors. Xwin-LM incorporates several key components:
XwinLM-SFT: These are base models initially fine-tuned using high-quality instruction data.
Xwin-Pair: This is a large-scale dataset containing multi-turn conversations with preference labels meticulously created using GPT-4.
XwinRM: These are reward models trained on the Xwin-Pair dataset, available in sizes of 7B, 13B, and 70B parameters.
Xwin-Set: This is a multi-choice preference dataset where each prompt has 64 unique responses generated by XwinLM-SFT, each scored by the corresponding Xwin-RM model.
XwinLM-RS: These are models further fine-tuned using the highest-scoring responses identified in Xwin-Set.
XwinLM-DPO: These models are further optimized on Xwin-Set using a technique called Direct Preference Optimization (DPO).
Evaluations on benchmark datasets like AlpacaEval and MT-bench show consistent and significant improvements across this entire pipeline. This demonstrates the effectiveness and scalability of the Xwin-LM approach for aligning large language models.
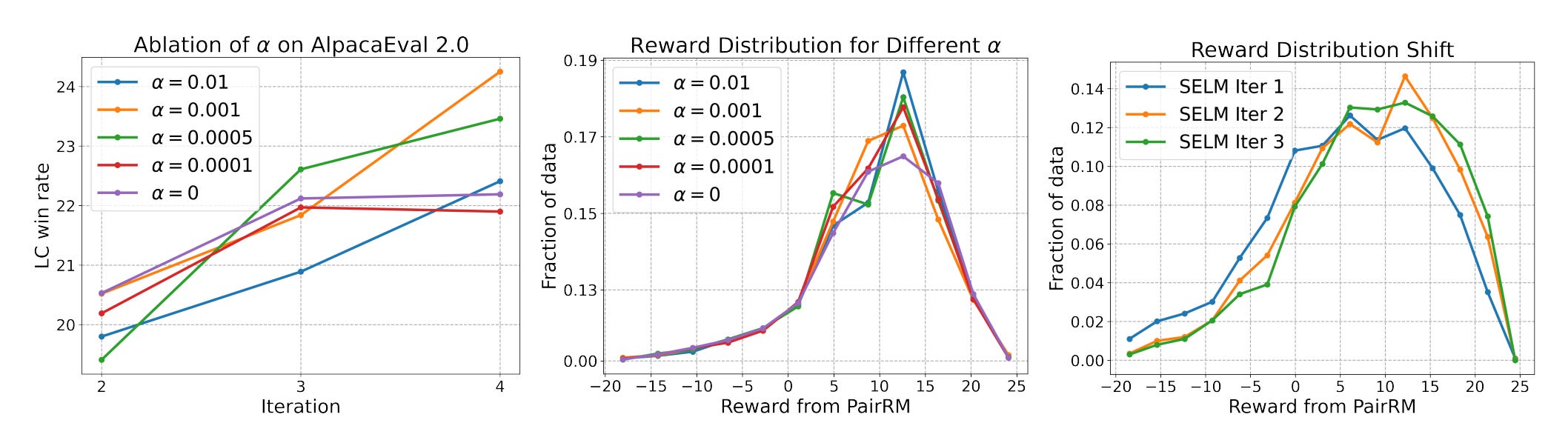
Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
Summary: Recent advances in aligning Large Language Models (LLMs) with human intents have showed promise, notably in preference optimization approaches such as Reinforcement Learning from Human Feedback (RLHF). This strategy uses human or AI input on model outputs to iteratively enhance model alignment. However, one significant problem is developing a complete reward model, which necessitates studying a huge area of alternative language outputs in order to represent various human preferences.
Standard RLHF approaches frequently use random sampling from existing LLMs, which might be wasteful for investigating a wide variety of responses. To overcome this issue, researchers suggested Self-Exploring Language Models (SELM). SELM addresses this issue by actively promoting study of potentially lucrative portions of the language space. This is accomplished by a two-part goal that prioritizes replies with a bigger potential reward.
Unlike traditional techniques, which need a separate reward model (RM), SELM includes this function directly into its goal. This streamlines the training process and enables iterative modifications to the LLM. SELM outperforms prior approaches such as Direct Preference Optimization (DPO) in terms of exploring varied outcomes while lowering bias towards previously undiscovered linguistic patterns. Experiments demonstrate that fine-tuning SELM on big models such as Zephyr-7B-SFT and Llama-3-8B-Instruct greatly increases performance on benchmarks focusing on instruction following (MT-Bench and AlpacaEval 2.0), as well as a variety of other academic benchmarks. These findings illustrate SELM's capacity to successfully match LLMs with human preferences.
AI Image Generation: deepai.org
Prompt: Ford mustang in space
