Top AI Research Papers - Last Week
Top AI Research Papers - Last Week
July 29 - August 4, 2024

ARCLE: THE ABSTRACTION AND REASONING CORPUS LEARNING ENVIRONMENT FOR REINFORCEMENT LEARNING
Summary: The paper describes ARCLE, an environment created to support reinforcement learning research on the Abstraction and Reasoning Corpus (ARC). Addressing this inductive reasoning standard with reinforcement learning involves problems such as a large action space, a difficult goal, and a diverse set of assignments. The authors show that an agent utilizing proximal policy optimization can learn individual tasks with ARCLE. The use of non-factorial policies and auxiliary losses resulted in performance improvements, successfully reducing concerns related to action spaces and goal accomplishment. Based on these findings, the authors suggest many research avenues and motives for utilizing ARCLE, such as MAML, GFlowNets, and World Models.

MindSearch: Mimicking Human Minds Elicits Deep AI Searcher
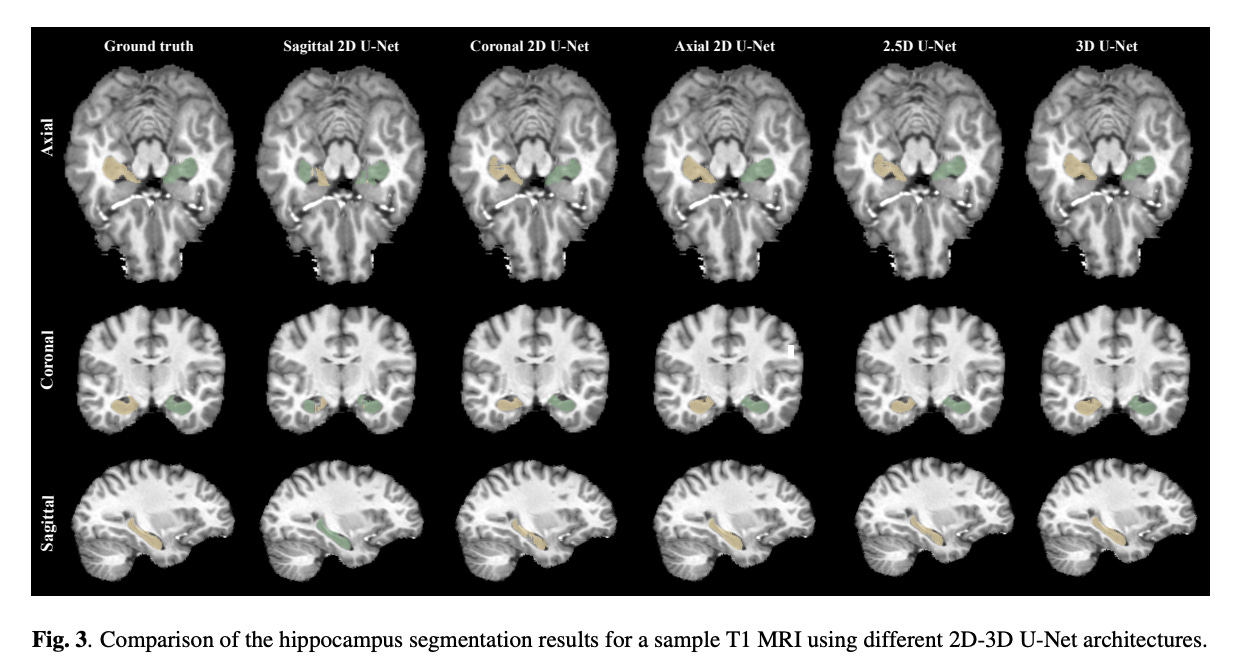
Summary: Information searching and integration is a complicated cognitive endeavor that takes a great amount of time and effort. Inspired by the extraordinary growth of Large Language Models (LLMs), new research has sought to overcome this problem by integrating LLMs with search engines. However, these systems still show insufficient performance due to three major challenges: (1) Complex requests are frequently unable to be accurately and completely retrieved by the search engine in a single attempt, (2) relevant information that must be integrated is scattered across multiple web pages, along with significant noise, and (3) the large number of web pages with lengthy content can quickly exceed the maximum context length of LLMs.
Inspired by the cognitive processes that people utilize to tackle these challenges, the authors present MindSearch, a system meant to emulate human cognitive processes in web information discovery and integration. MindSearch is implemented using a basic yet effective LLM-based multi-agent architecture. The WebPlanner agent simulates the human mind's multi-step information-seeking process as a dynamic graph construction task: it divides the user query into atomic sub-questions, which serve as nodes in the graph, and gradually expands the graph depending on WebSearcher search results.
Practical Video Object Detection via Feature Selection and Aggregation
Summary: Compared to still image object recognition, video object detection (VOD) presents distinct issues because to considerable across-frame fluctuation in object appearance and diversified degradation in certain frames. In principle, detection in one video frame might benefit from information in subsequent frames, making good feature aggregation over several frames critical to addressing the target problem. Most modern aggregation algorithms are intended for two-stage detectors, which have large computational costs due to their dual-stage construction. While one-stage detectors have made significant advances in processing static pictures, its application to VOD remains unexplored.
To overcome these challenges, the paper proposes a simple but efficient feature selection and aggregation technique that delivers large accuracy increases while incurring minimum computing costs. To decrease the huge compute and memory consumption associated with dense prediction in one-stage object detectors, the study first condenses candidate features from dense prediction maps. The relationship between a target frame and its reference frames is then assessed to inform the aggregation process.

rLLM: Relational Table Learning with LLMs
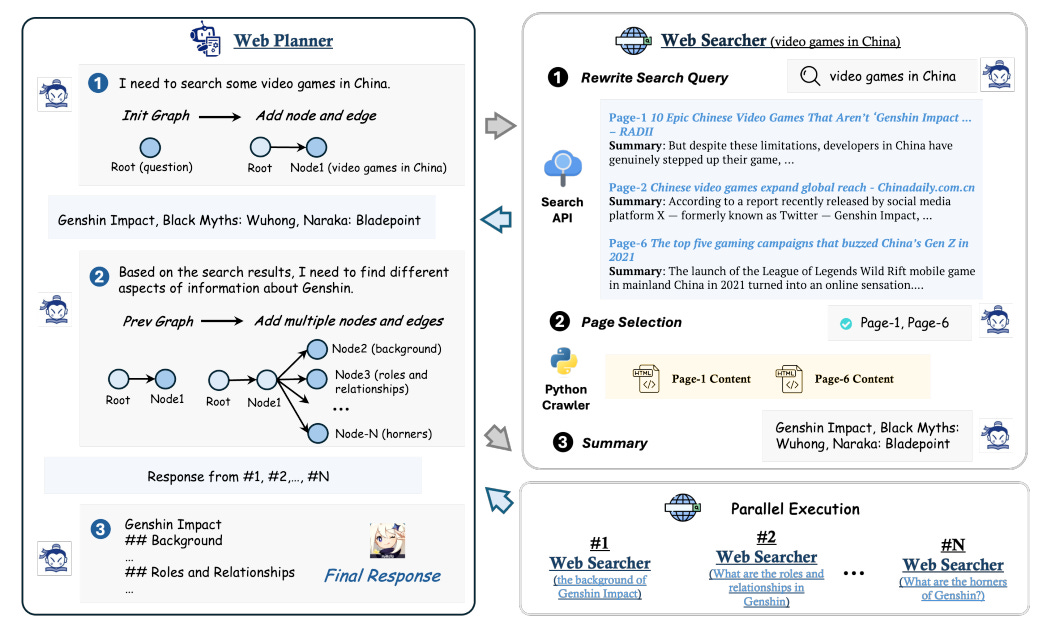
Summary: The authors introduce rLLM (relationLLM), a PyTorch library designed for Relational Table Learning (RTL) with Large Language Models (LLMs). The core idea behind rLLM is to decompose state-of-the-art Graph Neural Networks, LLMs, and Table Neural Networks into standardized modules, allowing for the rapid construction of novel RTL-type models through a simple "combine, align, and co-train" approach. To demonstrate the usage of rLLM, the authors introduce a straightforward RTL method called BRIDGE. Additionally, they present three novel relational tabular datasets (TML1M, TLF2K, and TACM12K) by enhancing classic datasets. The authors aim for rLLM to serve as a useful and easy-to-use development framework for RTL-related tasks.
YUCCA: A DEEP LEARNING FRAMEWORK FOR MEDICAL IMAGE ANALYSIS
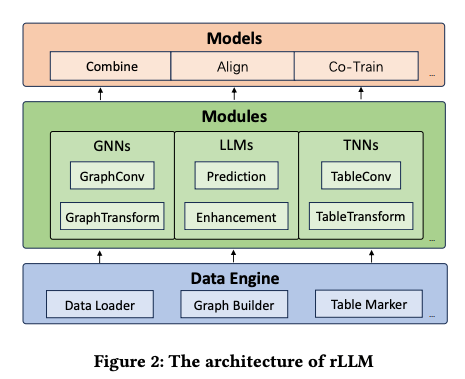
Summary: Medical image analysis utilizing deep learning frameworks has enhanced healthcare by automating hard activities; yet, many existing frameworks lack flexibility, modularity, and usability. To solve these issues, the authors provide Yucca, an open-source AI platform developed exclusively for medical imaging applications and accessible at https://github.com/Sllambias/yucca. Yucca, built on PyTorch and PyTorch Lightning, has a three-tiered architecture: functional, modules, and pipeline, providing a complete and customized solution.
Yucca has been tested on a variety of tasks, including brain micro-bleed detection, white matter hyper-intensity segmentation, and hippocampus segmentation, yielding cutting-edge results while exhibiting its resilience and adaptability. Yucca is a strong, adaptable, and user-friendly platform for medical image analysis, and the authors welcome community contributions to expand its capabilities and effect.