

Zero Shot Learning - Research Paper Review
Zero Shot Learning - Research Paper Review

Research Paper: GNDAN: Graph Navigated Dual Attention Network for Zero-Shot Learning
Authors: Shiming Chen , Ziming Hong, Guosen Xie , Qinmu Peng , Xinge You , Senior Member, IEEE, Weiping Ding , Senior Member, IEEE, and Ling Shao , Fellow, IEEE
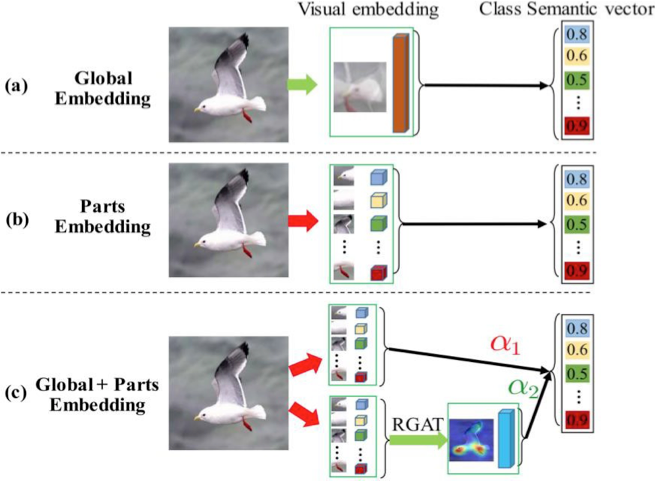
Novel Approach: Graph Navigated Dual Attention Network (GNDAN)
Summary: GNDAN represents a novel approach to ZSL in computer vision.
Learning Discriminative Visual Embeddings: GNDAN focuses on learning visual embeddings that are effective at distinguishing different visual features. These embeddings are crucial for understanding and classifying images based on their content.
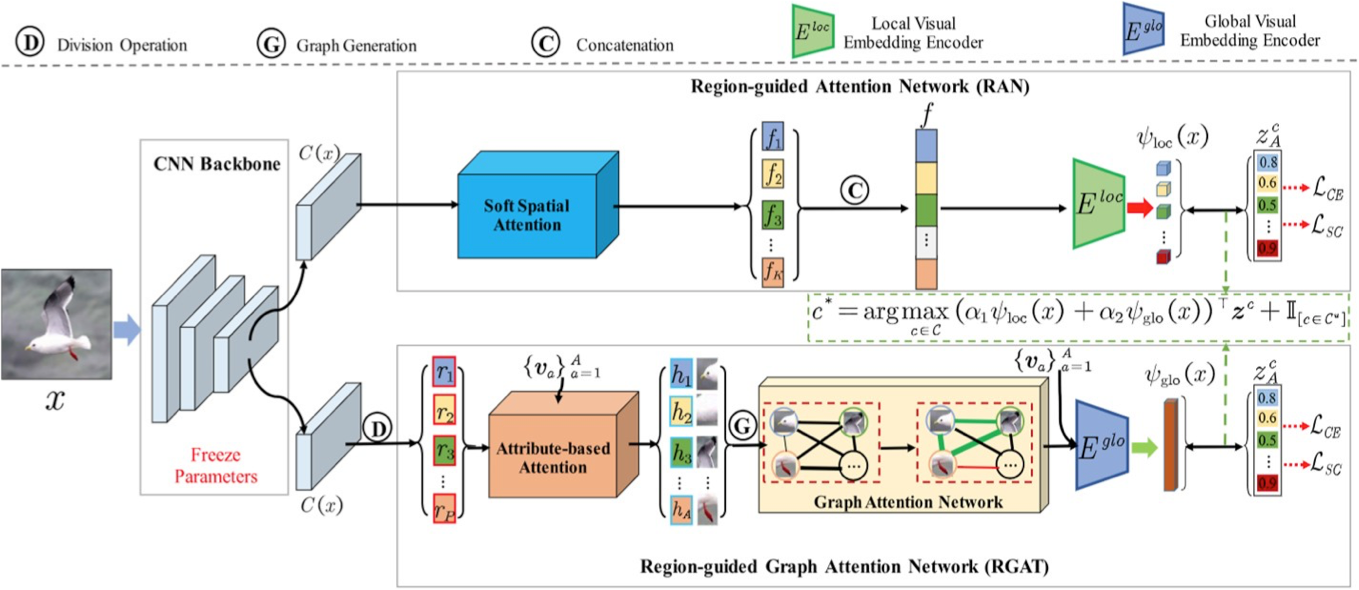
Components of GNDAN: RAN (Region-guided Attention Network):To identify and focus on specific regions of an image that are most important for generating accurate local embeddings.
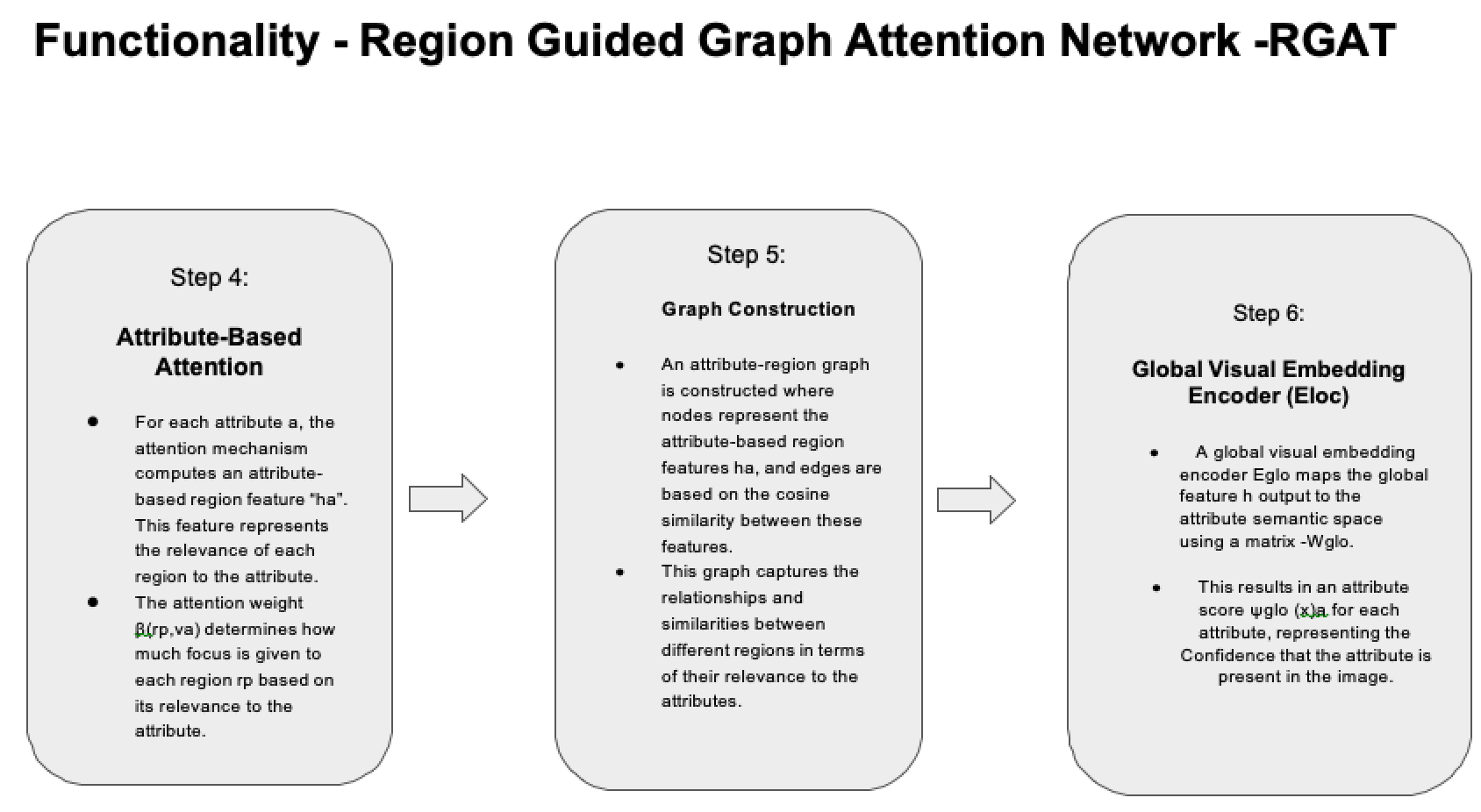
RGAT (Region-guided Graph Attention Network): To capture and utilize global context by exploiting the relationships between different attribute-based region features within an image.
Attribute-Region Graph Representation: The method introduces a novel representation where relationships between attribute-based region features are captured in a graph format. RGAT uses this graph to learn explicit global embeddings that capture the overall structure and relationships of features in the image
Zero Shot Learning
Zero-shot learning (ZSL) - The aim is to recognize new classes during learning by
exploiting the intrinsic semantic relatedness between seen and unseen classes.
ZSL methods can be categorized into:-
1. Conventional ZSL (CZSL), which aims to predict unseen classes
2. Generalized ZSL (GZSL), which can predict both seen and unseen classes
3. Inductive ZSL (IZSL) only utilizes the labeled seen data to predict unseen classes.
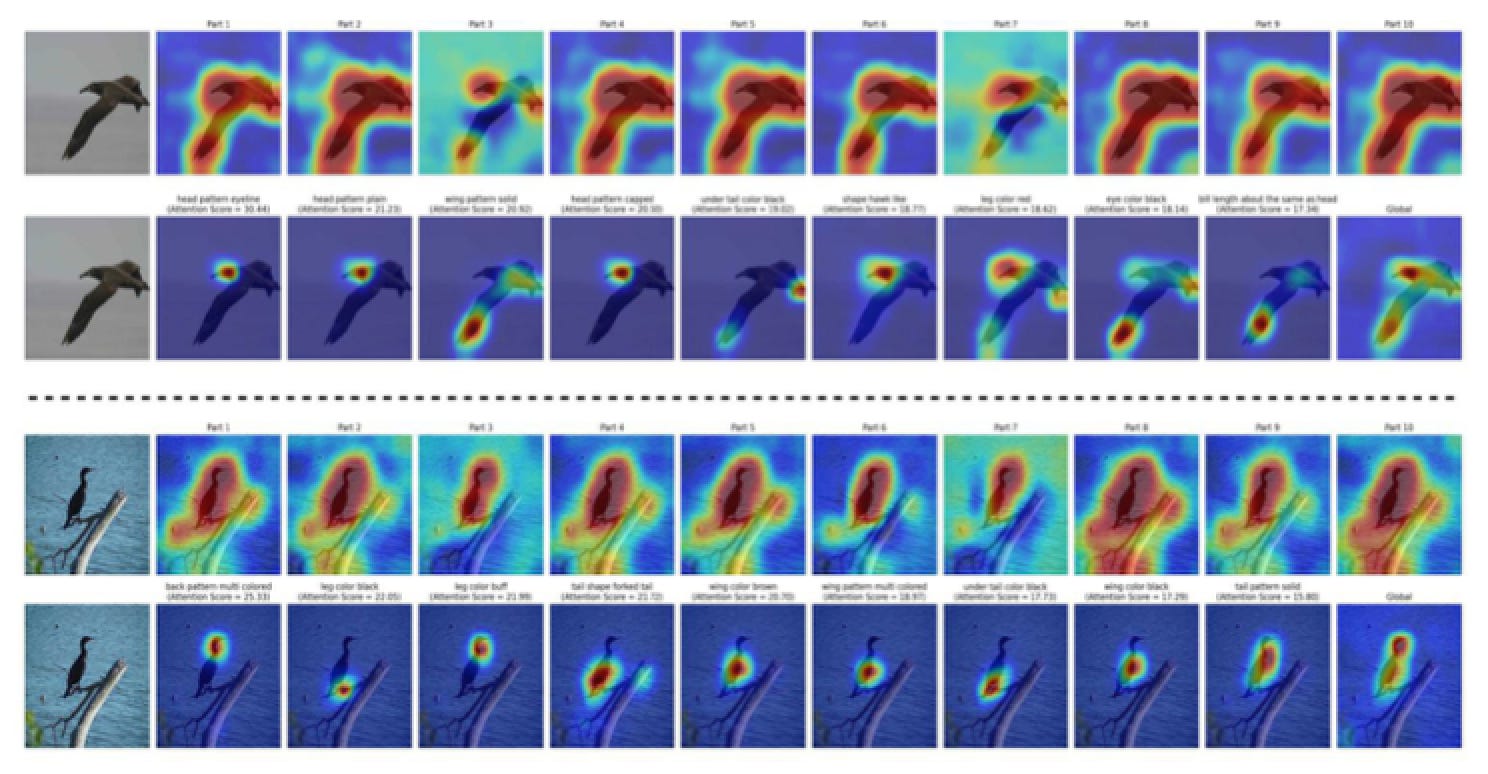
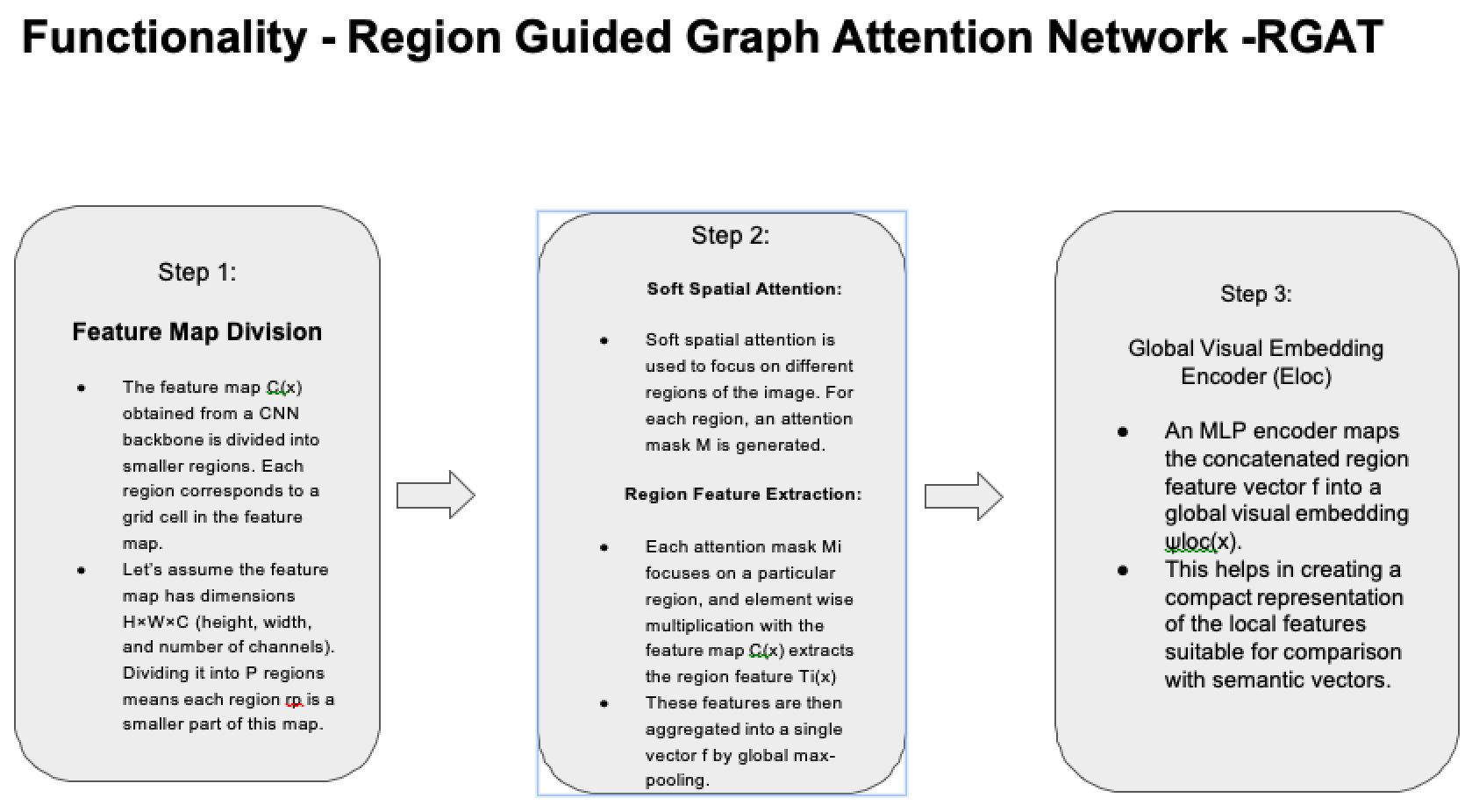
Region-Guided Attention Network (RAN)
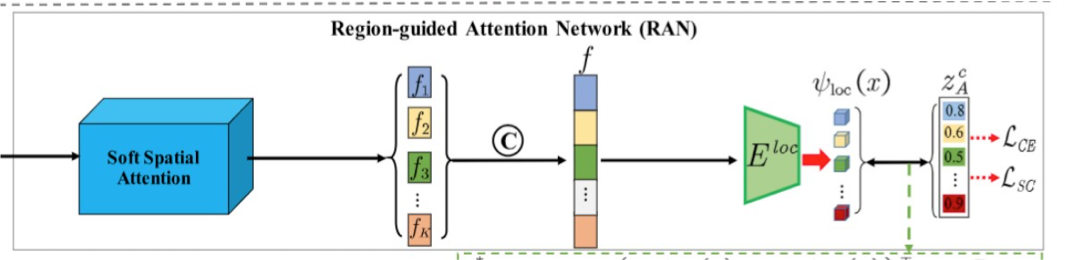
How does Region Guided Attention Network (RAN) work?
Step 1: Input Image: The image of the bird flying in the sky is fed into the network.
Step 2: Attention Mechanism:
● The soft spatial attention mechanism analyzes the entire image and assigns different importance (attention weights) to different regions of the image.
● For example, the region containing the bird might get higher attention weights compared to the sky in the background, because the bird is the key object we are interested in.
Step 3: Discovering Discriminative Regions:
● The attention mechanism identifies discriminative regions, such as the bird’s eyes, legs, and body, which are essential for recognizing that the object in the image is a bird.
● Less important areas like the background sky, clouds, receive lower attention weights.
Step 4: Generating Local Embeddings:
● These high-attention regions (bird’s body parts) are then used to create local embeddings, which are compact and informative representations of these
regions.
● Each embedding captures the critical features needed to distinguish the bird from other objects.
Step 5: Use in Zero-Shot Learning:
● These embeddings are then used to match against semantic descriptions of "bird" (from seen classes) to recognize the unseen class (bird).
Algorithm - RAN
Soft Spatial Attention - It helps in identifying and focusing on important regions of an image to create local embeddings
Step 1: Input Image Representation:
Feature Map: The input image ‘x’ is processed by a CNN backbone. It extracts a feature map C(x) of size H×W×C,
Where:- H and W are the height and width of the feature map, C is the number of feature channels.
Step 2: Attention Mask Generation:
1×1 Convolution: Apply a 1×1 convolution on the feature map C(x) to produce a set of K attention masks. Each mask Mi(x) highlights a different region of the image.
Sigmoid Activation: The convolution output is passed through a sigmoid activation function to ensure that the attention masks are in the range [0, 1].
Formula:
M = Sigmoid (Conv1×1(C(x))
where M is a tensor of size K×H×W
Step 3: Region Feature Extraction: Apply Masks: Each attention mask Mi(x) is used to select and emphasize specific regions in the feature map C(x). This is done by element-wise multiplication:
Formula:
Ti(x) = C(x) ⊙ R(Mi(x)), where R(⋅) expands Mi(x) to the size of C(x) and ⊙ denotes element-wise multiplication.
Step 4: Local Visual Embedding Encoder: The local visual embedding encoder (Eloc) maps the concatenated region feature vector f to a lower-dimensional semantic space, creating the local visual embedding.
1. MLP Architecture:
Structure: The encoder Eloc is a multilayer perceptron (MLP) with the following layers:
Input: K×C dimensional vector.
Hidden Layer: 4096 dimensions.
Output Layer: A dimensions, where A is the number of attributes.
2. Local Embedding Computation:
Embedding Generation: Pass the concatenated region feature vector f through Eloc to obtain the local visual embedding ψloc(x).
3. Formula:
ψloc(x)=Eloc(f)
Findings: Eloc is particularly effective when the semantic vector's dimensionality is low, such as A=85 on the Animals with Attributes (AWA) dataset and A=102 on the SUN dataset.
Region Guided Graph Attention Network (RGAT)
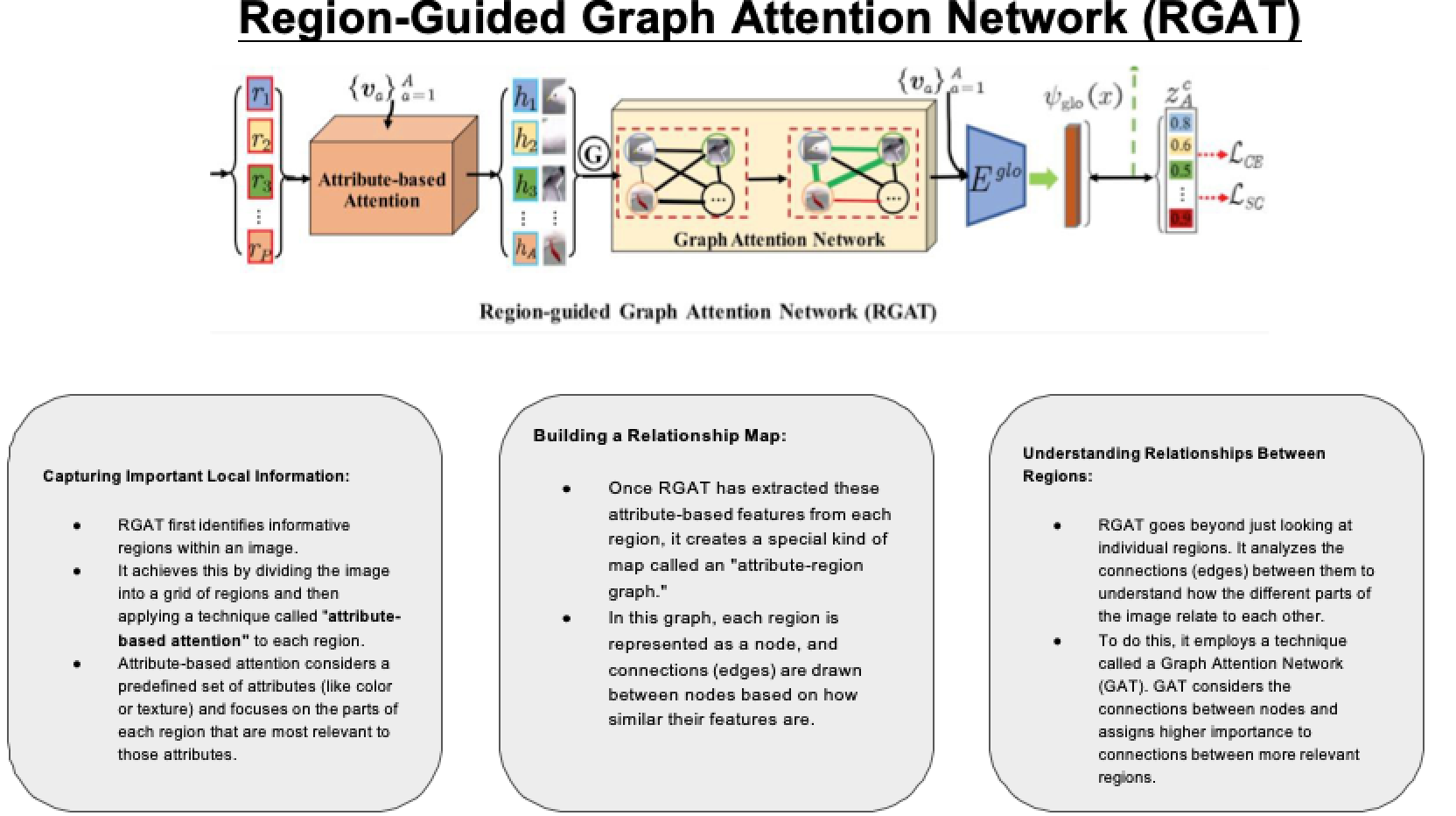
Model Architecture
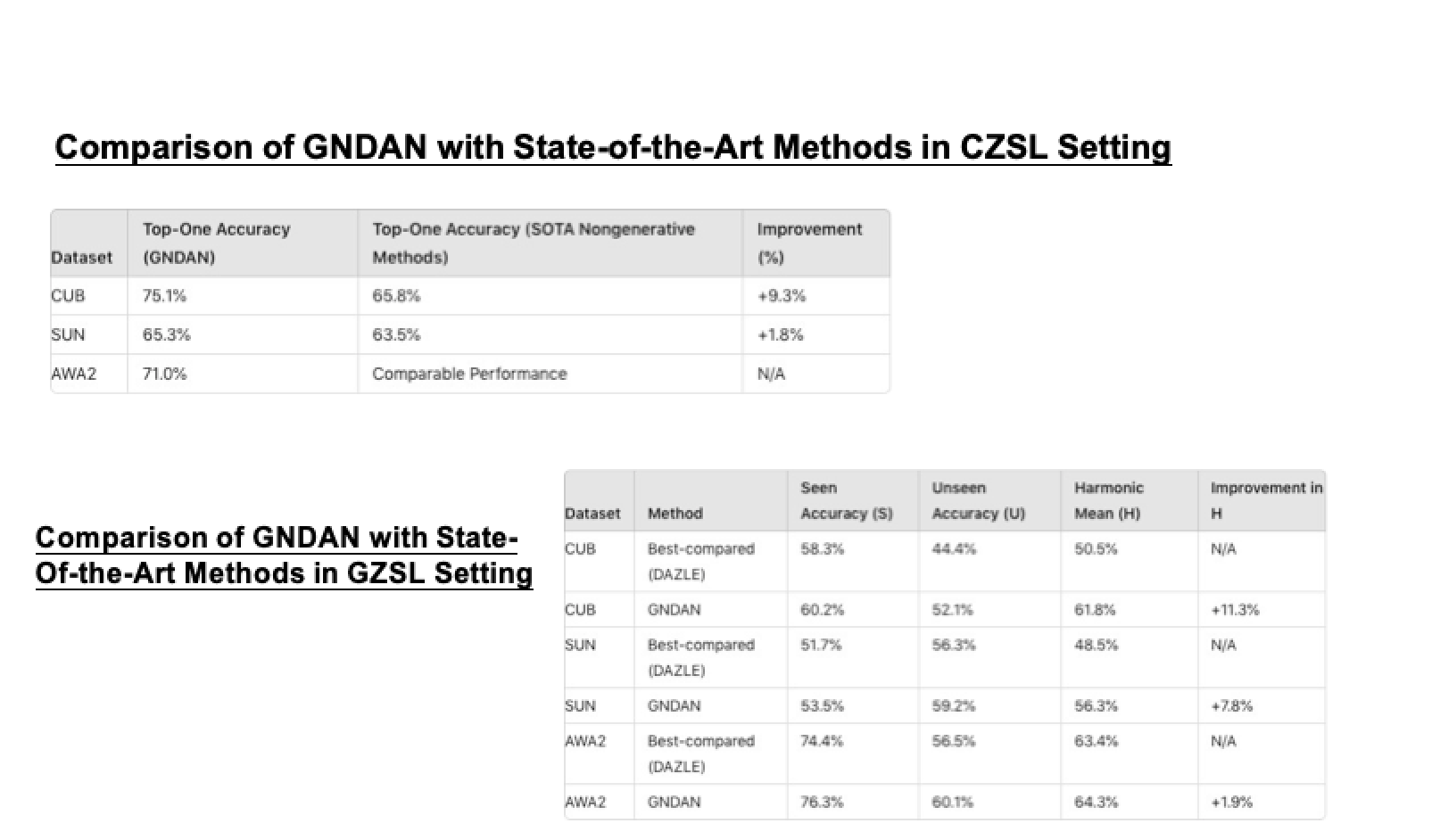
Results
I thoroughly enjoyed reviewing this paper. You can find the full published paper HERE
Zero-Shot Learning is a method that enables learning new categories without any samples. Typically, a model can only recognize the categories it has seen in the training set. However, through zero-shot learning, the model can leverage auxiliary information for reasoning and generalize to categories it has never encountered. This auxiliary information can include semantic descriptions of the categories, attributes, or other prior knowledge.