5 Research papers quietly powering Agentic AI!
Top Agentic papers

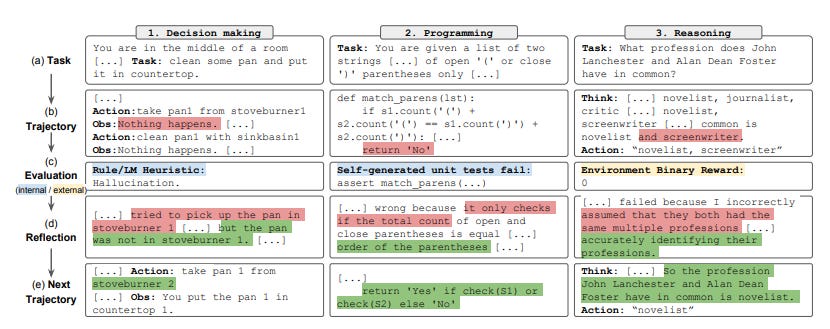
A Roadmap for Building Autonomous Agents using Foundation Models
Summary: This survey reviews the emerging field of autonomous agents built upon Large Language Models (LLMs), which leverage vast knowledge for human-like reasoning, moving beyond traditional agents trained in isolated environments. The authors propose a unified architectural framework for constructing these agents, systematically breaking them down into four key modules: profiling, memory, planning, and action. It provides a comprehensive overview of agent applications in social science, natural science, and engineering, alongside methods for capability acquisition like fine-tuning and mechanism engineering. Finally, the paper details subjective and objective evaluation strategies and outlines critical challenges, including prompt robustness, hallucination, and the need for generalized human alignment.
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
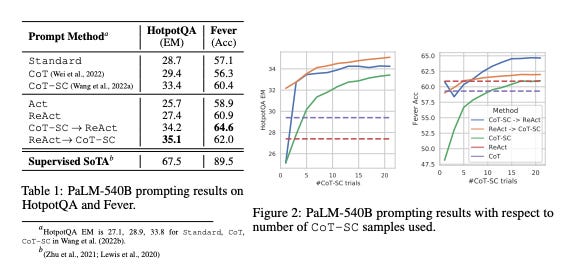
Summary: This paper introduces ReAct, a method that enables large language models (LLMs) to synergize reasoning and acting by generating both reasoning traces and task-specific actions in an interleaved manner. This approach allows reasoning to guide actions, helping to induce, track, and update plans, while actions enable interaction with external sources like APIs to gather information and ground the reasoning process. On knowledge-intensive tasks like question answering, ReAct significantly reduces issues of hallucination and error propagation found in reasoning-only methods by interacting with a Wikipedia API. In interactive decision-making benchmarks like ALFWorld and WebShop, ReAct substantially outperforms specialized imitation and reinforcement learning agents, improving success rates by 34% and 10% respectively, using only a few in-context examples.
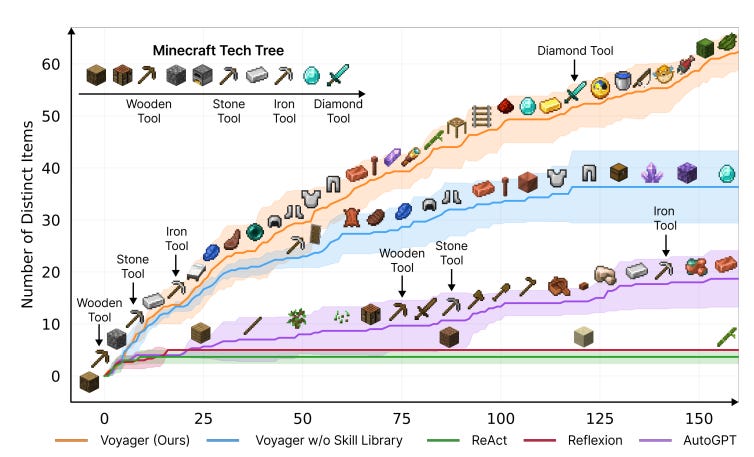
VOYAGER: An Open-Ended Embodied Agent with Large Language Models
Summary: This paper introduces VOYAGER, the first LLM-powered embodied agent designed for lifelong learning in open-ended worlds like Minecraft, capable of continuous exploration and skill acquisition without human intervention. VOYAGER operates using three key components: an automatic curriculum that suggests progressively challenging tasks, an ever-growing skill library of reusable code representing complex behaviors, and an iterative prompting mechanism for program improvement. The agent leverages GPT-4 to generate executable code, which is then refined based on environmental feedback, execution errors, and a self-verification module that confirms task completion. Empirically, VOYAGER significantly outperforms prior methods by discovering 3.3× more unique items, advancing through the technology tree up to 15.3× faster, and successfully generalizing its learned skill library to solve novel tasks in new environments.
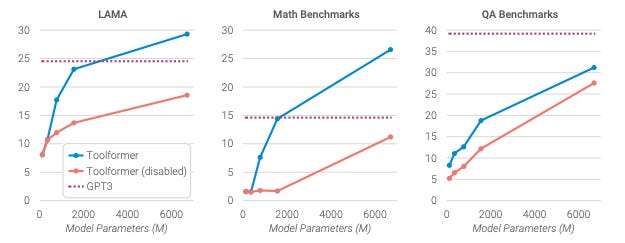
Toolformer: Language Models Can Teach Themselves to Use Tools
Summary: This paper introduces Toolformer, a language model trained to teach itself how to use external tools like calculators, search engines, and Q&A systems through simple APIs. The model learns in a self-supervised fashion by first annotating a large language modeling dataset with potential API calls, then filtering these calls by keeping only those that provably help in predicting future tokens. This process enables Toolformer to learn which APIs to call, what arguments to pass, and how to best integrate the results into its text generation without requiring large-scale human annotation. The resulting model substantially improves zero-shot performance on a variety of downstream tasks, including mathematical reasoning and question answering, often outperforming much larger models while preserving its core language modeling capabilities.
Reflexion: Language Agents with Verbal Reinforcement Learning
Summary: This paper introduces Reflexion, a novel framework that reinforces language agents through linguistic feedback rather than by updating model weights. The core mechanism involves agents verbally reflecting on task feedback signals (like success/failure or errors), creating a textual summary of the experience, and storing it in an episodic memory buffer. This reflective text is then added to the agent's context in subsequent trials, helping it learn from past mistakes and improve its decision-making. Reflexion significantly boosts performance across diverse tasks, achieving a 91% accuracy on the HumanEval coding benchmark, which surpasses the previous state-of-the-art, by efficiently learning from trial-and-error.