
Data Cleansing Steps in Python
Introduction to Data Pre-processing

Image Source: https://lab.getapp.com/importance-of-data-cleaning-and-governance/
It is one of the most important steps in model building. During any model building process, we start with reading the input data, understanding the data, exploring data (Data Types, Data format etc.)
Essential steps in Data Cleansing
1. Standardization of data
2. Data type conversion
3. Eliminating errors in the input dataset
4. Removal of non-essential data from input
5. Dealing with redundant data/ duplicate values
6. Dealing with missing values in the input dataset
7. Dealing with Outliers in the dataset
1. Standardization of data
This step deals with fixing Inconsistent column names and converting it into a standard format.
Input Data

i) Load the input.csv file into a dataframe and rename columns for standardization.
Standardize all column names

ii) If there are large number of columns to be changed, use functions such as str.strip(), str.lower() & str.replace() as shown below:-
df.columns = df.str.strip().str.lower().str.replace(‘ ’, ‘ _ ’).str.replace( ‘ ( ’ , ’ ’).str.replace(‘ ) ’, ‘ ‘)
str.lower( ) — It converts all column names to lowercase.
str.replace( ) — It can be used to replace values. Ex:- str.replace( ‘ ( ’ , ’ ’), here ( is replaced with space.
Standardize individual column


2) Data Type Conversion
It is essential to have uniform datatype across all values of the given column. The datatype conversion can be performed using apply( ).


Here, the age column is of float datatype. It can be converted into int64 as
df[‘age’] = df[‘age’].apply(np.int64)
3) Eliminating Errors in input dataset
Removal of grammatical errors using str.replace( )

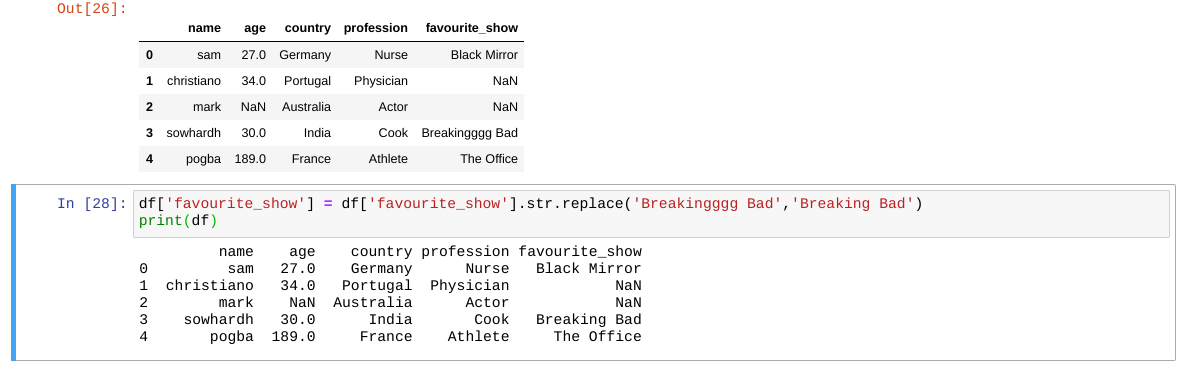
4) Removal of non-essential data from input.
Remove unnecessary columns in the dataframe as follows using df.drop( ):


In order to drop multiple columns at a time, use the following approach

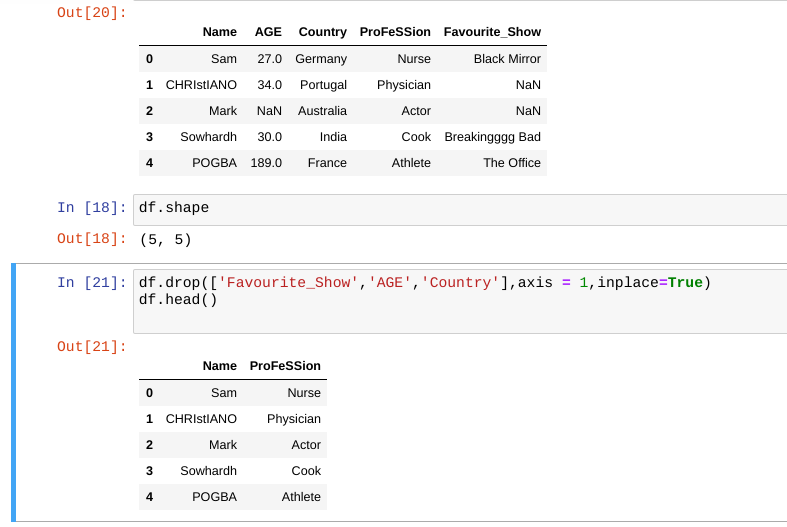
5. Dealing with redundant data/ duplicate values
In the above example, the dataframe does not have any duplicates. We have also examined for duplicates in a single column above.


6. Dealing with Missing values in input data
Initially, we check for missing records in each column. This approach is not feasible when dealing with huge data.
Input Data


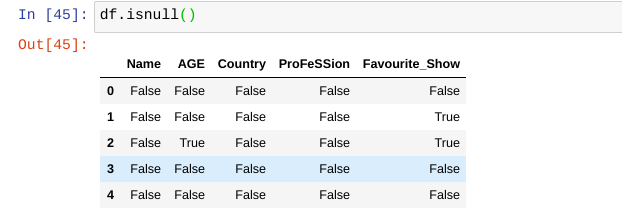
To check if there are any Missing Values in the entire dataframe


Total number of missing values in our dataframe


You can use dropna to drop rows/columns with missing values based on a threshold
The Missing data can be filled with 0’s as well as follows:-
df 2 = df.copy()
df3 = df2.fillna(0)
How to deal with missing data?
Drop Missing values
Fill the missing values with test statistic
Predict the missing value with a ML algorithm and replace it.
7. Dealing with Outliers

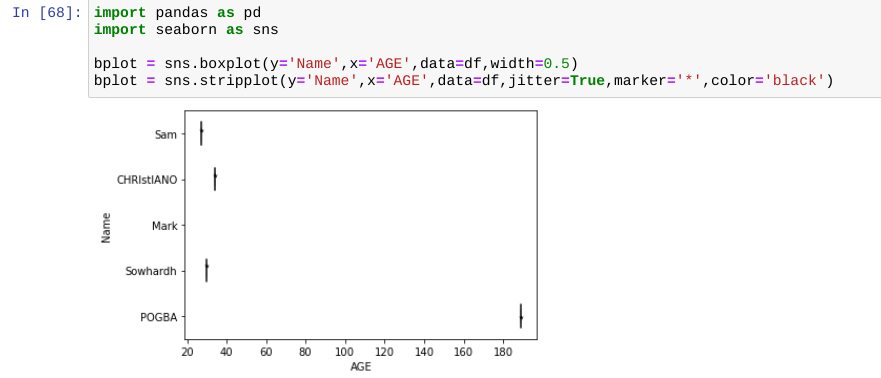
1. Imputation
Imputation of missing values with mean / median / mode.
2. Capping (IQR)
For missing values, we could cap it by replacing those observations outside the lower limit with the value of 5th %ile and those that lie above the upper limit, with the value of 95th %ile.
Q1 = Outliers — df.quartile(0.05)
Q2 = Outliers-df.quartile(0.95)
IQR = Q2 — Q1
3. Prediction
The outliers can be replaced with missing values (NA) and then can be predicted by considering them as a response variable.