
Data Pre-Processing : Transformations for Individual Predictors
Theme of the month : Foundations of Data Science

Data pre-processing procedures generally involve the addition, deletion, or change of a training data set. Data processing can make or break a model's predictive capability. Transformations to lessen the impact of data skewness or outliers can result in significant performance improvements. Feature extraction is an empirical technique for generating surrogate variables that are composites of numerous predictors. Simpler tactics, such as deleting predictors due to a lack of information, can also be beneficial. The type of model chosen determines the amount of data pre-processing required. Some approaches, like tree-based nodes, are noticeably indifferent to predictor data characteristics. Other approaches, such as linear regression, are not.
Today's bulletin discusses one of the approaches to unsupervised data processing.
Centering and Scaling
Centering and scaling enhance the numerical stability and performance of machine learning algorithms by ensuring that features have comparable ranges and contribute equally. They prevent higher values from dominating the learning process and make distance measures more consistent in algorithms that rely on them. Furthermore, these modifications improve the efficacy of regularization procedures. Following are the techniques for centering and scaling.
Centering:
Subtracts the average predictor value from all values.
Results in the predictor having a zero mean.
Scaling:
Divides each value of the predictor variable by its standard deviation.
Results in a common standard deviation of one for the data.
Purpose: Improves the numerical stability of calculations.
Downside:
Loss of interpretability of individual values.
Data are no longer in their original units.
Transformations to Resolve Skewness
Another prominent use for transformations is to eliminate distributional skewness.
An unskewed distribution is generally symmetric. This suggests that the chances of falling on either side of the distribution mean are approximately equal. A right-skewed distribution has more points on the left side of the distribution than on the right.
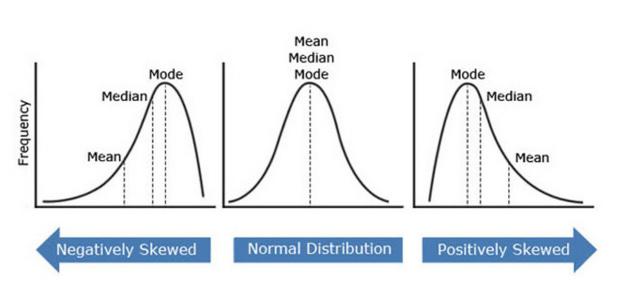
A typical rule of thumb for determining skewed data is that if the ratio of the highest to lowest number is greater than 20, the data has significant skewness. The skewness statistic can also be used to make a diagnosis. If the predictor distribution is essentially symmetric, the skewness approaches zero. As the distribution becomes more right-skewed, the skewness statistic increases. Conversely, if the distribution is left skewed the statistic becomes negative.
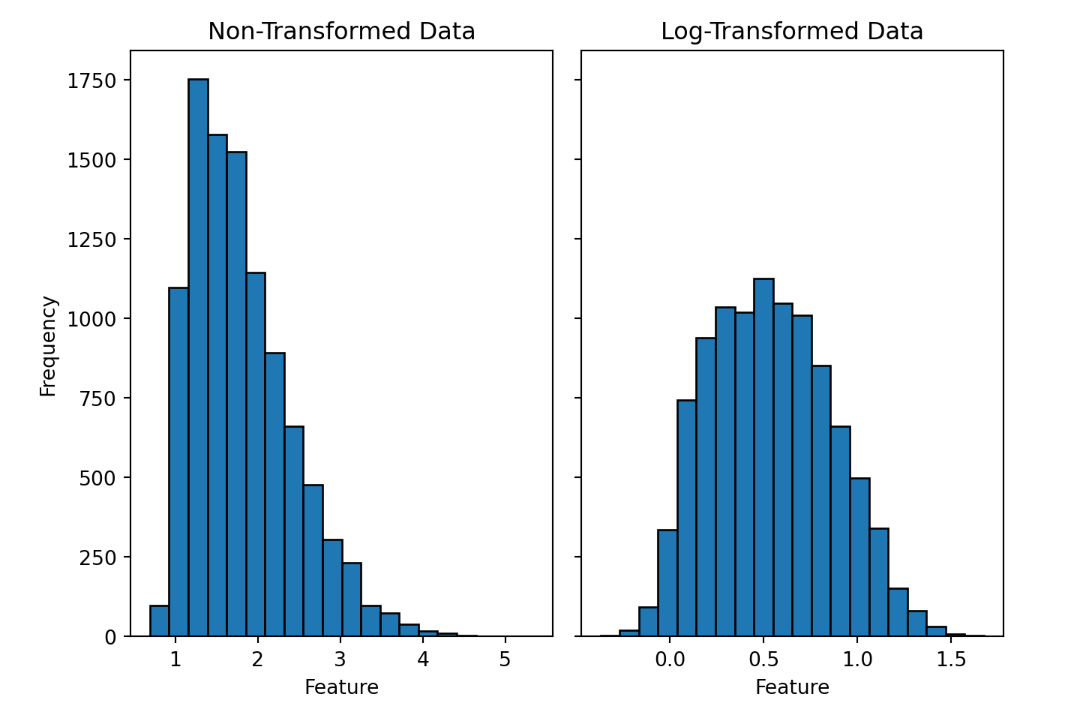
Replacing the data with log, square root, or inverse may aid in removing the skewness. However, these strategies should only be used after serious consideration of the problem at hand. The image below depicts the skewed distribution after log transformation is applied. After the transformation, the data is not completely symmetric, but it behaves better with typical ML methods than it did in natural units.
What’s New Today?
Microsoft's AI-Powered Bing and Edge Expansion: Microsoft announced the next generation of its AI-powered Bing and Edge. Key updates include eliminating the waitlist for Bing, introducing richer visual and multimodal search capabilities, and enhancing productivity with features like chat history and persistent chats. Bing Image Creator now supports over 100 languages, and Edge will have improved document summarization and AI-driven actions (The Official Microsoft Blog).
AI & Big Data Expo North America 2024: The AI & Big Data Expo, scheduled for June 5-6, 2024, in Santa Clara, will showcase the latest innovations in AI and big data. Over 7,000 attendees, including top executives and industry professionals, will discuss topics like Responsible AI, AI personalization, and enterprise AI adoption (AI Expo).
World Economic Forum's AI Innovations: The World Economic Forum highlighted significant AI innovations, emphasizing their transformative impact across various industries, including healthcare, finance, and manufacturing. Discussions focused on ethical AI and the importance of responsible AI practices (World Economic Forum).