
Implement Google’s BERT on Colab -Part 2


Image Source: https://searchengineland.com/welcome-bert-google-artificial-intelligence-for-understanding-search-queries-323976
BERT
It stands for -Bidirectional Encoder Representations from Transformers
Lets dig deeper and try to understand the meaning of each letter.
B (Bidirectional) — The framework learns from both the left and right side of a given word. This makes it better than the LSTMs which are uni-directional in nature (Left to Right or vice versa).
Same words having different contexts is termed as “Homonym”. BERT deals with homonyms by understanding the context.
E(Encoder) — An encoder program which is used to learn the representations from a given dataset.
R(Representations) -They are learnt from the given dataset
T (Transformers) — The BERT model is based on the Transformer architecture.
Why is BERT sooo good?
BERT has transformed the NLP world with it’s head turning performance on NLP tasks. The secret recipe behind this mind boggling performance is it’s training data.
BERT’s Training data
-Google’s Book Corpus (800 Million words)
-Wikipedia (2500 Million words)
Implementing BERT on Google Colab
Let’s implement Sentiment Classifier on Movie Reviews
The input dataset is obtained from: http://ai.stanford.edu
Step 1: Install ktrain library (Although most of the libraries are pre-installed on Google Colab, some are not :(.. )
Step 2: Import necessary Packages

The goal is to train BERT model on positive and negative movie reviews and create a Sentiment Classifier. Load the data with Keras wrapper from tensorflow as shown below

In the above code, get_file (downloads a file from URL), origin (represents the URL), extract = True (download file from the archive of dataset).
Step 3: Set path of dataset

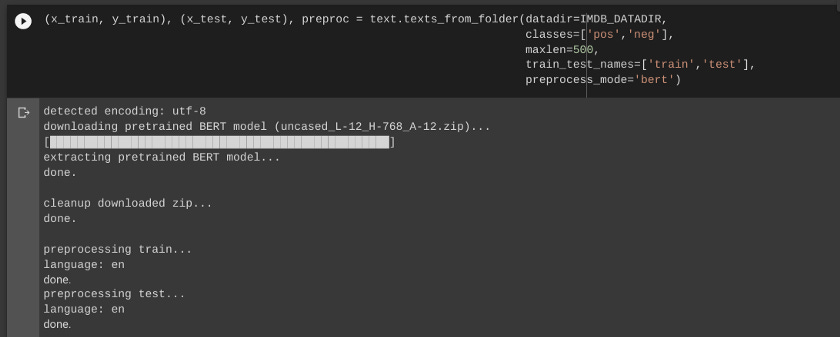
Step 4: Creating Training and Test sets
In order to create the test and train set for BERT, “text” function in the ktrain library plays a prominent role. It helps to separate the texts into 2 classes in our case (Positive reviews and Negative Reviews). ktrain is a wrapper around Keras.
Step 5: Building BERT model (Text Classification)

The function we use here is “text_classifier” to build and return a Text Classifier.
Multi-Label = False because we only have 2 categories in our case (Positive and Negative reviews).
Maxlen is 500 means this is the maximum number of word-ids
Step 6: Training BERT model

Training the BERT model happens through the “learner” function present in the ktrain library.
Batch_size = 6 (This is the documentation recommended batch size based on max word length/ max sequence length which is 500 in our case).
Run using TPU on Colab. Do not increase the number of epochs or you will face Resource Allocation Error from Colab!
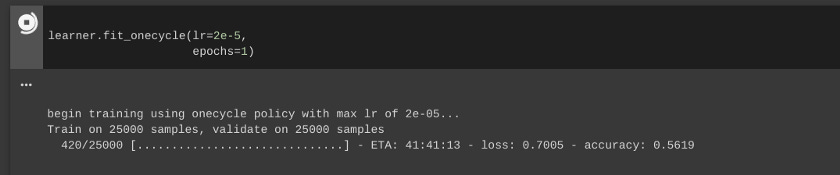
The Training is on 25000 movie review samples and it will be validated on 25000 validation samples. As you can see above, the ETA to completely train and validate 25000 samples is about 41 mins with TPU. This doesn’t even run on GPU. I’ll update the validation accuracy screenshot of BERT once the training and validation is completed.
Based on BERT’s reputation, the expected validation accuracy is (90% +)
Happy Reading …:)
41 mins LOL!... not so fast, bro! :))) you need some "code dancing" to make ktrain use TPU