
Introduction to Google's BERT (Part -1)


Image Source: https://searchengineland.com/welcome-bert-google-artificial-intelligence-for-understanding-search-queries-323976
BERT is an acronym for Bidirectional Encoder Representations from Transformers. By the end of 2018, new Natural Language Processing technique based on Transformers revolutionized Deep Learning community
Background Research -BERT development
The lack of training data is usually the biggest challenge in Natural Language Processing tasks. Even though we have a lot of text data, we have to create unique datasets by splitting it from a large dataset. This results in shortage of labelled training data. Natural Language Processing model performance increases with the increase in training data.
Research was performed on several techniques to create language representation models through training on unannotated text on the web. This process is termed as Pre-training. The pre-trained models can be used to perform NLP tasks on task specific datasets. This is a much more efficient process than training a model from scratch based on a small domain based dataset. This approach provides great model accuracy improvements.
BERT shocked the Deep Learning world when it produced State of the Art results on many of the NLP tasks. The best part of BERT is, it is downloadable and free to use.
Idea behind BERT?
Language models are usually based on contextual sentence completion. Before BERT, we used to analyze sentences from left to right & vice versa to predict and fill in the missing word in the sentence but BERT is bi-directionally trained. This is what makes BERT stand out from the rest.
The bi-directional quality of BERT was a major improvement by heaps and bounds compared to single-direction language models.
BERT uses an innovative Masked LM (MLM) approach. The concept of Masked LM is that it randomly masks words in a sentence and tries to predict them. The model looks in both the directions to figure out the semantic Context and then tries to fill the masked word. BERT takes into consideration the previous and the next word in the sentence while performing prediction of the masked word at the same time. This simultaneous bi-directional lookup is what made BERT better than the LSTMs.
What makes BERT so powerful?
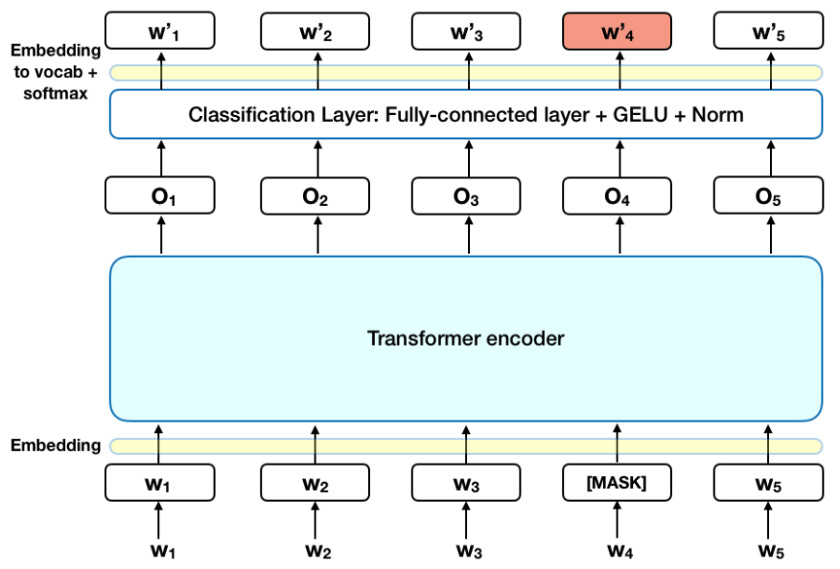
Image Source: https://searchengineland.com/welcome-bert-google-artificial-intelligence-for-understanding-search-queries-323976
The non-directional approach — Pre-trained language representations can be context-free or context specific. Context based representation can be unidirectional/bi-directional. Context-free models like word2Vec create word embedding for single word representations. BERT makes a context-based model deeply bi-directional.
BERT is based on Transformer model Architecture instead of LSTMs. Transformer -The basic functionality of Transformers is to perform a large number of small steps. Each step has an ATTENTION mechanism to understand the inter-relation between all the words in the sentence
How does BERT work?
BERT is based on Transformers, the attention mechanism which understands the contextual relationship between words in a sentence. Transformer has an encoder to read input text and a decoder to produce the word prediction. The input of encoder in BERT is a Sequence of Tokens which is converted into vectors and processed using Neural Networks.
The input is accompanied with additional metadata. The different types of embeddings of tokens for the sentences are as follows:-
1. Token Embedding — [CLS] token is added at the beginning of each sentence and a [SEP] token is added at the end of the sentence.
2. Segment Embedding — A marker which indicates each sentence is added to the token. The encoder can understand the number of sentences present.
3. Positional Embedding — It indicates the position to each token in the sentence.
Input Representation of BERT is as follows:-
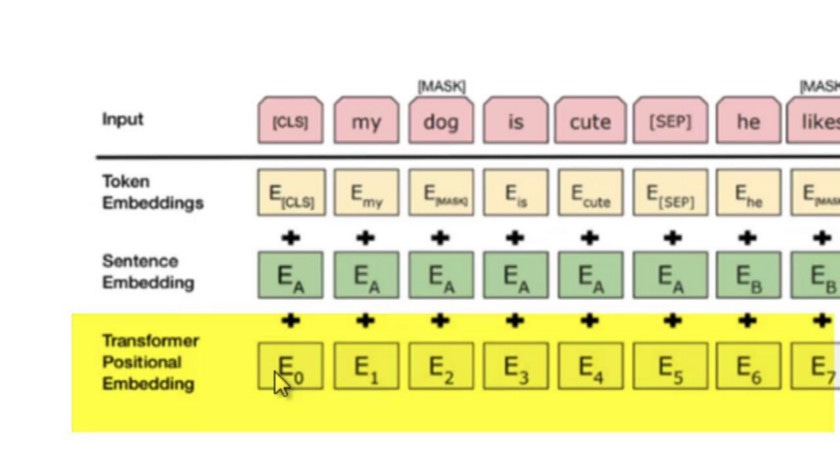
Image Source:
Transformers can help stack these sequences so that the output is a sequence of vectors. BERT does not predict the next word in the sentence.
Masked LM (MLM) — It randomly masks out 15% of the input words and replaces it with the [MASK] token. The input sentence is then passed through BERT attention based encoder, where the process is to predict the masked words based on the unmasked words in the sentence. It only tries to predict for [MASK] tokens to get rid of them.
Out of the 15% of tokens selected for masking, 80% of the tokens are replaced with [MASK] token, 10% are replaced with random token and 10% of the tokens are left unchanged.
Next Sentence prediction -BERT Training also performs Next sentence prediction, which is mostly used in the Question-Answering systems. During training, BERT gets a pair of sentences and it learns to predict if the second sentence is actually the second sentence in the original sequence. BERT is trained such that 50% of the time, the second sentence comes after the first and 50% of the time, it is just a random sentence occurring in the text and BERT predicts if the second sentence is random or not. Complete input sentence goes through the Transformer model.
Happy Reading :)