


Speech Emotion Detection using Voice & Transcribed Text — Part 1

Proposed Model: Deep Dual Recurrent Encoder Model
The proposed model simultaneously uses “Transcript text data” and Audio features to understand the Emotions associated with Speech. The model would have the ability to analyze speech data from “Signal Level” to “Language level”. This approach is a unique way of using Deep learning model for “Statistical Speech Processing”.
Challenges in Speech Analytics
1. Training data — Insufficient data points to train Deep learning architecture is one of the biggest challenges in Speech Analytics
2. The characteristics of speech must be learnt from Low-level speech signals which is a difficult task to achieve with audio features like MFCC, Low level descriptor features alone.
The proposed deep learning solution uses High level text transcription and low-level audio signal characteristics which makes it feasible for better Speech analytics.
Audio features from Speech
1. Mel Frequency Ceptral Co-efficient
2. Low Level Descriptors obtained from raw audio signal.
Deep Learning Architecture
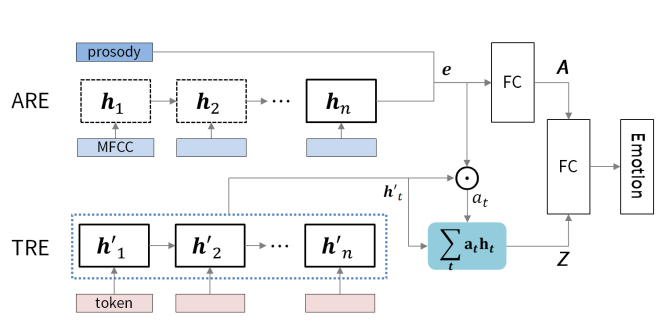
The proposed Deep learning architecture has 2 components: -
1. Audio Recurrent Encoder (ARE)
2. Text Recurrent Encoder (TRE)
Audio Recurrent Encoder (ARE)
Features extracted from the raw audio signal like MFCC, LDDs are passed into a gated Recurrent Neural Networks. The Hidden state consists of Time series patterns of these audio features. The hidden state can be represented as:-
H(t) = f(h(t-1) — x(t))
Where,
H(t) = Internal Hidden state of RNN
f() = RNN function with a weight parameter.
The last hidden state (h) is the representative Vector that contains all of the sequential audio data.
(h + p) = e [Additional Informative Vector representation].
Where,
P = Additional prosodiac features.
Audio Feature Extraction
The MFCC and Prosodiac features can be obtained using a tool called “openSMILE”.
Results of Audio Recurrent Encoder (ARE)
The emotion function is determined by applying “Softmax” function to vector “e”.
Y(i) = Softmax (e^T*M + b),
L = — log Sum (i=1: N) y(i), clog(y^(i), c)
Where,
e = Calculated Vector Representation of the Audio signal.
b = bias
C = Total number of Classes.
N = Total number of samples used in “Training”.
Text Recurrent Encoder (TRE)
The transcription text can be obtained through multiple ASR techniques.
Workflow of Speech Transcription
Raw Audio signal Speech Transcript Tokens are “Indexed into a Sequence” using nltk.
Each token is then passed through a “Word-embedding” layer that converts a word index to a corresponding 300-dimension vector that contains additional Contextual meanings between words.
The sequence of embedded tokens is fed into the “Text Recurrent Encoder”.
The predicted “Target class of emotion” is represented as: -
Y(i) = Softmax (h (last)^T *M + b)
Where, h (last) is the Last Hidden State.
To be continued in Part-2..
Happy Learning 😊.
Subscribe to us : datagalore.substack.com