


Top 5 AI Research Papers
Dec 1 - Dec 9, 2024

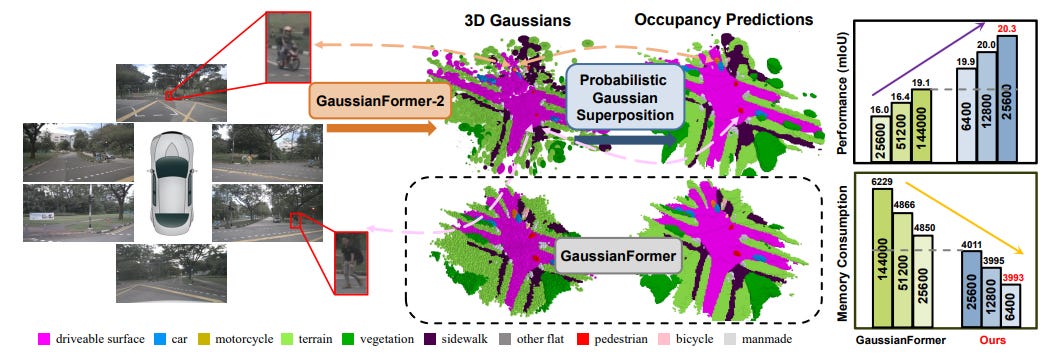
GaussianFormer-2: Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Summary: The task of 3D semantic occupancy prediction is essential for advancing vision-based autonomous driving, as it enables the detailed understanding of both geometry and semantics in the surrounding environment. Many existing methods rely on dense grid-based scene representations, which fail to consider the sparse nature of driving scenes. Although 3D semantic Gaussians provide a sparse, object-centric alternative, they often inefficiently represent empty regions. To overcome these challenges, a new probabilistic Gaussian superposition model is introduced. This model interprets each Gaussian as representing the probability of occupancy within its neighborhood and uses probabilistic multiplication to construct the overall scene geometry. For semantic prediction, an exact Gaussian mixture model is employed to minimize unnecessary overlap between Gaussians.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Summary: Infinity introduces a groundbreaking approach to high-resolution, photorealistic image generation guided by language instructions through its Bitwise Visual AutoRegressive Modeling framework. This model redefines visual autoregressive methods by employing a bitwise token prediction mechanism enhanced with an infinite-vocabulary tokenizer and classifier, paired with a bitwise self-correction system. These innovations greatly enhance generation fidelity and detail. By theoretically extending the tokenizer's vocabulary size to infinity and scaling the transformer architecture, Infinity significantly amplifies the scaling capabilities beyond conventional visual autoregressive models. This advancement enables Infinity to set a new benchmark for autoregressive text-to-image models, surpassing leading diffusion models such as SD3-Medium and SDXL.
Infinity demonstrates remarkable performance improvements, elevating the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, with a win rate of 66% over SD3-Medium. Additionally, it generates high-quality 1024x1024 images in just 0.8 seconds, achieving a speed 2.6 times faster than SD3-Medium and establishing itself as the fastest text-to-image model to date.

VisionZip: Longer is Better but Not Necessary in Vision Language Models
Summary: VisionZip introduces a novel solution to the challenges posed by the redundancy of visual tokens in vision-language models. While recent advancements have improved performance by increasing the length of visual tokens often far exceeding the length of text tokens—this approach significantly inflates computational costs. Popular vision encoders like CLIP and SigLIP generate visual tokens with substantial redundancy, limiting their efficiency. To address this, VisionZip employs a straightforward yet effective strategy to select a subset of informative visual tokens for input to the language model. This reduces token redundancy, enhances computational efficiency, and preserves model performance. VisionZip is versatile and can be applied across various image and video understanding tasks, as well as in multi-turn dialogues where many existing methods falter.
Experimental evaluations demonstrate that VisionZip surpasses previous state-of-the-art methods, achieving at least a 5% performance gain across nearly all tested settings. Additionally, it significantly accelerates model inference, reducing prefilling time by 8x. Notably, VisionZip enables the larger LLaVA-Next 13B model to infer faster than the smaller LLaVA-Next 7B model while delivering superior results.

TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
Summary: TokenFlow introduces a groundbreaking unified image tokenizer designed to bridge the gap between multimodal understanding and image generation, addressing a long-standing challenge in the field. Previous attempts to unify these tasks often relied on reconstruction-targeted Vector Quantization (VQ) encoders, which struggle due to the differing granularities of visual information required for understanding and generation. This mismatch creates a trade-off that significantly hampers performance in multimodal understanding tasks.
To overcome this limitation, TokenFlow employs an innovative dual-codebook architecture that decouples semantic and pixel-level feature learning while ensuring alignment through a shared mapping mechanism. This approach allows TokenFlow to provide direct access to both high-level semantic representations for understanding tasks and fine-grained visual features for generation, using shared indices to bridge the two. Extensive experiments validate TokenFlow's effectiveness across various tasks. It achieves a 7.2% average improvement over LLaVA-1.5 13B in multimodal understanding, marking the first instance of discrete visual input surpassing this benchmark. For image reconstruction, TokenFlow attains an impressive FID score of 0.63 at 384×384 resolution. Additionally, it delivers state-of-the-art performance in autoregressive image generation, achieving a GenEval score of 0.55 at 256×256 resolution, comparable to the leading SDXL model.

HunyuanVideo: A Systematic Framework For Large Video Generative Models
Summary: HunyuanVideo represents a significant milestone in video generation by introducing a high-performance open-source video foundation model that rivals, and in some cases surpasses, the capabilities of leading closed-source models. While recent advancements in video generation have had a profound impact across industries and daily life, the dominance of closed-source solutions has created a substantial gap between public and industry-accessible technologies. HunyuanVideo addresses this disparity by providing a robust open-source alternative.
The HunyuanVideo framework integrates critical components, including meticulous data curation, advanced architecture, progressive model scaling and training techniques, and an efficient infrastructure optimized for large-scale model training and inference. This comprehensive approach enabled the development of a video generative model with over 13 billion parameters, making it the largest open-source video model to date.
The model's capabilities have been rigorously tested through extensive experiments and targeted designs, ensuring exceptional visual quality, realistic motion dynamics, precise text-video alignment, and the application of advanced filming techniques. Professional evaluations confirm that HunyuanVideo outperforms state-of-the-art models, including Runway Gen-3, Luma 1.6, and three leading Chinese video generation models.
