


Top AI Papers - Last week
January 1 - January 6, 2025

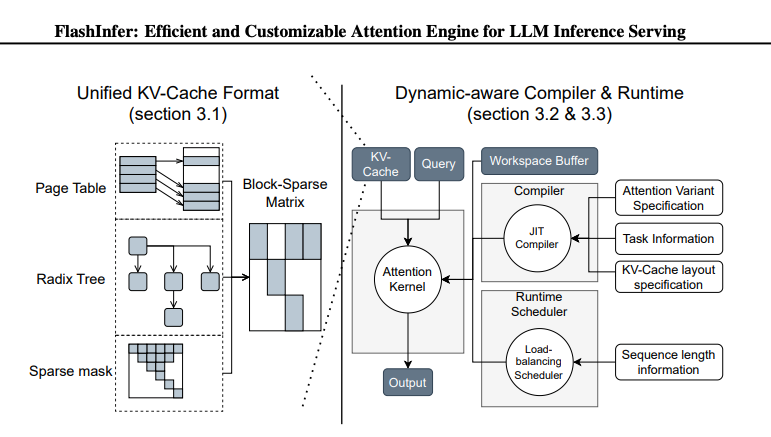
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Summary: Large language models (LLMs) rely on transformers powered by attention mechanisms. Scaling these models demands efficient GPU attention kernels for faster and smoother inference. FlashInfer is a cutting-edge attention engine designed to enhance LLM serving performance. It addresses memory inefficiencies with block-sparse and composible KV-cache formats. This reduces redundancy and optimizes memory access across diverse applications. FlashInfer’s customizable templates allow adaptation to various workloads via JIT compilation. A load-balanced scheduling algorithm ensures smooth handling of dynamic user requests. It seamlessly integrates with CUDAGraph, balancing static and dynamic configurations. FlashInfer is already embedded in frameworks like SGLang, vLLM, and MLC-Engine. Tests show it significantly improves performance in real-world scenarios. FlashInfer reduces latency by 29-69% over current solutions and speeds up parallel generation by up to 17%. It is a versatile, high-performance tool driving the future of LLM serving.
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
Summary: Latent diffusion models using Transformers produce high-quality images but face challenges in balancing reconstruction and generation performance. Increasing the visual tokenizer’s feature dimension enhances image quality but demands larger models and more training, leading to inefficiencies. This trade-off often results in visual artifacts or incomplete convergence due to high computational costs. The issue arises from the difficulty of learning high-dimensional latent spaces. To resolve this, the proposed VA-VAE aligns latent spaces with pre-trained vision models, improving tokenizer efficiency. This approach accelerates the training of Diffusion Transformers (DiT) in complex latent spaces. LightningDiT, an enhanced DiT baseline, leverages VA-VAE for faster, more effective image generation.

VoiceRestore: Flow-Matching Transformers for Speech Recording Quality Restoration
Summary: VoiceRestore is a new method for enhancing speech recordings using flow-matching Transformers trained on synthetic data. It addresses multiple types of degradation, such as noise, reverberation, and compression, with a single model. By applying conditional flow matching and classifier-free guidance, VoiceRestore improves speech quality without needing paired clean and degraded data. The model learns to transform degraded audio into high-quality recordings through a self-supervised process. We outline the training process, flow matching framework, and model architecture. VoiceRestore generalizes well to real-world tasks, restoring both short clips and long recordings. Evaluations confirm its flexibility and effectiveness across diverse audio conditions.

2.5 Years in Class: A Multimodal Textbook for Vision-Language Pre-training
Summary: A new multimodal textbook corpus has been introduced to improve Vision-Language Model (VLM) pre-training by utilizing instructional videos. Existing interleaved datasets, often sourced from webpages, are limited by low knowledge density and weak image-text alignment. In contrast, instructional videos offer richer, more coherent content with stronger logical connections between visual and textual elements. The corpus compiles 22,000 hours of class material drawn from 2.5 years of educational videos. An LLM-generated taxonomy guides the systematic collection and refinement of keyframes, audio transcriptions, and textual data. Organized in temporal order, the resulting dataset provides deeper knowledge integration and enhanced image-text coherence, supporting more effective VLM training.

TrustRAG: Enhancing Robustness and Trustworthiness in RAG
Summary: TrustRAG is a defense framework designed to protect Retrieval-Augmented Generation (RAG) systems from corpus poisoning attacks that can undermine large language model (LLM) performance. By filtering compromised content, TrustRAG ensures the integrity of external knowledge sources. The framework uses a two-stage process to detect and isolate malicious documents. First, K-means clustering identifies attack patterns through semantic embeddings. Second, cosine similarity and ROUGE metrics flag discrepancies between internal model knowledge and retrieved information. TrustRAG operates as a plug-and-play module, requiring no additional training, and integrates with both open and closed-source LLMs. This approach enhances RAG system resilience while preserving response accuracy and relevance.
