Top AI Papers -Last Week
Nov 4 - Nov 13, 2024

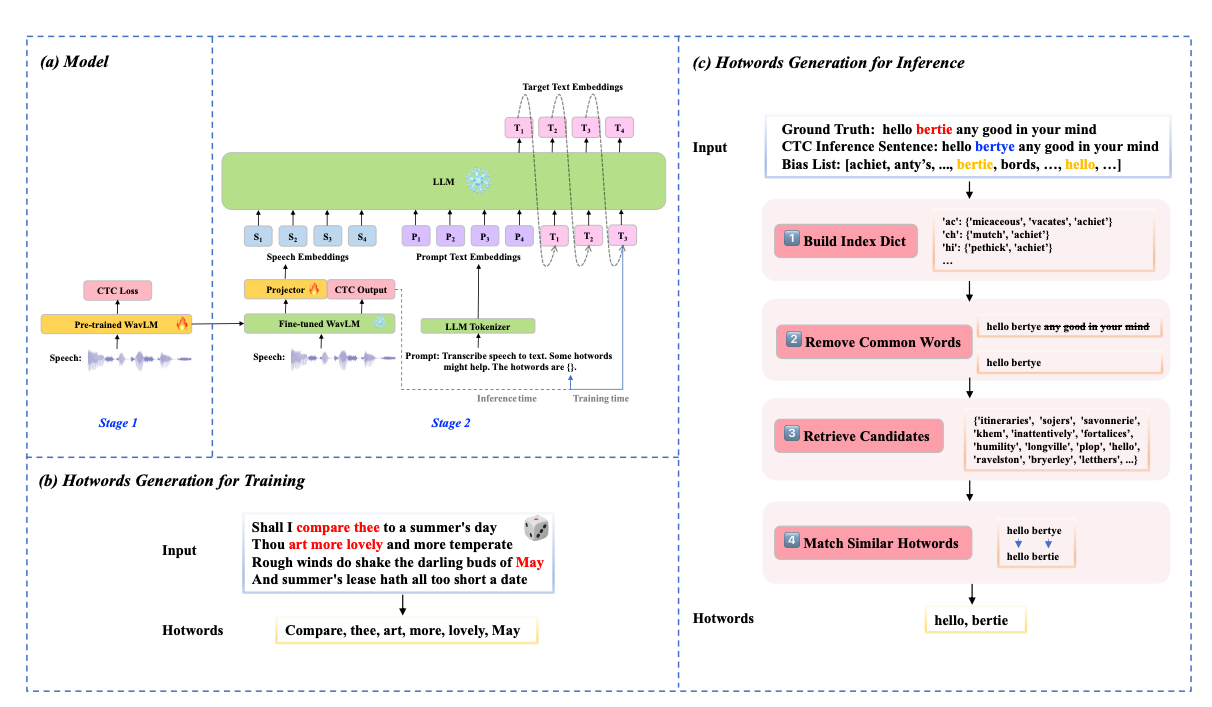
A Short Note on Evaluating RepNet for Temporal Repetition Counting in Videos
Summary: Several studies report that the RepNet model underperforms on certain repetition counting datasets. This issue was initially noted in the TransRAC paper, where a modified version of RepNet was tested. In Section 5.3, TransRAC details that the final fully connected layer of RepNet was altered to manage videos with more than 32 action periods, though the specifics of this modification are not clear. This change significantly reduced the model’s Off-by-One Accuracy (OBOA) on UCFRep and RepCount datasets, suggesting that the modified model could not accurately count repetitions in these datasets. Subsequent studies used these results from TransRAC but attributed them to RepNet, rather than the modified version.
The original RepNet model, however, can handle periods longer than 32 without modifications. This is achieved by the "Multi-speed Evaluation" technique, described in Section 3.5 of the original RepNet paper, which involves analyzing videos at various playback speeds, a method also applied in evaluating the Countix dataset and earlier studies. When tested on UCFRep and RepCount with this multi-speed approach, RepNet performs effectively, highlighting its robustness without needing layer modifications.
Token Merging for Training-Free Semantic Binding in Text-to-Image Synthesis
Summary: Text-to-image (T2I) models demonstrate impressive generation abilities but often struggle with accurately linking related objects and attributes from input prompts—a problem known as semantic binding. Existing solutions generally involve intensive model fine-tuning or require users or large language models to specify layouts, adding complexity. In this paper, semantic binding is defined as associating an object with its attributes (attribute binding) or linking it with related sub-objects (object binding).
The authors introduce Token Merging (ToMe), a novel approach that enhances semantic binding by merging relevant tokens into a single composite token, ensuring that objects, their attributes, and sub-objects share the same cross-attention map. To handle potential ambiguity in complex prompts, end token substitution is proposed as a complementary strategy. Additionally, two auxiliary losses—entropy loss and semantic binding loss—are introduced early in the T2I generation process to refine layout determination and composite token alignment, thereby improving generation accuracy. Extensive experiments validate ToMe’s effectiveness, especially in complex scenes involving multiple objects and attributes, where existing methods often fall short. Comparisons on the T2I-CompBench and a new GPT-4o object binding benchmark confirm its advantages.

The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
Summary: Language models excel on tasks within their training distribution but often falter with new problems requiring complex reasoning. This study explores test-time training (TTT)—a method that temporarily updates model parameters during inference using a loss derived from input data—as a way to boost reasoning abilities, using the Abstraction and Reasoning Corpus (ARC) as a benchmark.
Systematic experimentation reveals three essential factors for effective TTT: (1) initial fine-tuning on similar tasks, (2) the use of auxiliary task formats and augmentations, and (3) per-instance training. TTT enhances ARC task performance significantly, yielding up to a sixfold accuracy improvement over base fine-tuned models. Applied to an 8-billion-parameter language model, TTT achieves 53% accuracy on ARC’s public validation set, raising the state-of-the-art by nearly 25% for public, purely neural models. Ensembling TTT with recent program generation approaches further boosts public validation accuracy to 61.9%, on par with the average human score.
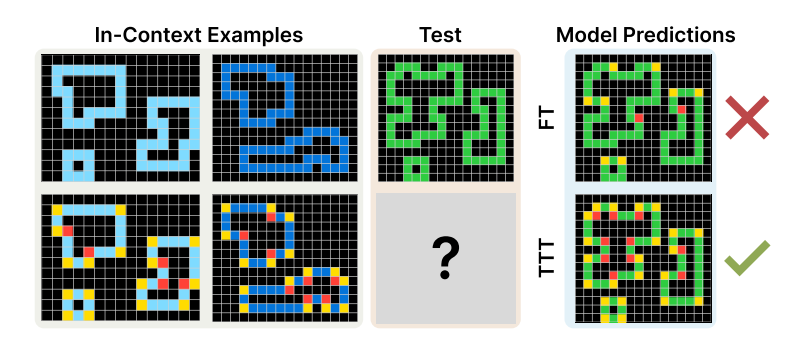
Scaling Mesh Generation via Compressive Tokenization
Summary: The authors introduce a compact yet powerful mesh representation, Blocked and Patchified Tokenization (BPT), enabling the generation of meshes with over 8,000 faces. BPT compresses mesh sequences through block-wise indexing and patch aggregation, reducing sequence length by approximately 75% compared to the original data. This compression breakthrough allows for the use of higher-face-count mesh data, enhancing detail and robustness in mesh generation. Leveraging BPT, the authors developed a foundational mesh generative model trained on scaled mesh data, allowing flexible control over point clouds and images. The model achieves state-of-the-art (SoTA) performance, generating meshes with detailed structure and accurate topology, positioning it for potential direct application in products.
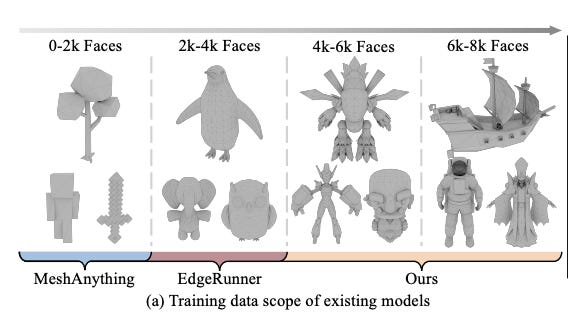
CTC-Assisted LLM-Based Contextual ASR
Summary: Contextual automatic speech recognition (ASR), or hot-word customization, is crucial for enhancing ASR accuracy on rare words. While current end-to-end (E2E) ASR systems perform well overall, they often struggle with recognizing uncommon terms. Standard E2E contextual ASR models typically have complex architectures and decoding processes that limit performance and make them vulnerable to distractor words. With large language model (LLM)-based ASR becoming more prevalent, the authors introduce a CTC-Assisted LLM-Based Contextual ASR model featuring an efficient filtering algorithm.
This model uses coarse CTC decoding to identify relevant hot-words, which are then incorporated into the LLM prompt, achieving word error rates (WER/B-WER) of 1.27%/3.67% and 2.72%/8.02% on the Librispeech test-clean and test-other sets for rare word recognition. These results significantly outperform the baseline LLM-based ASR model and other related methods. Notably, the model maintains strong performance even with up to 2,000 biasing words, highlighting its robustness and scalability.