


Top AI Papers of December 2024

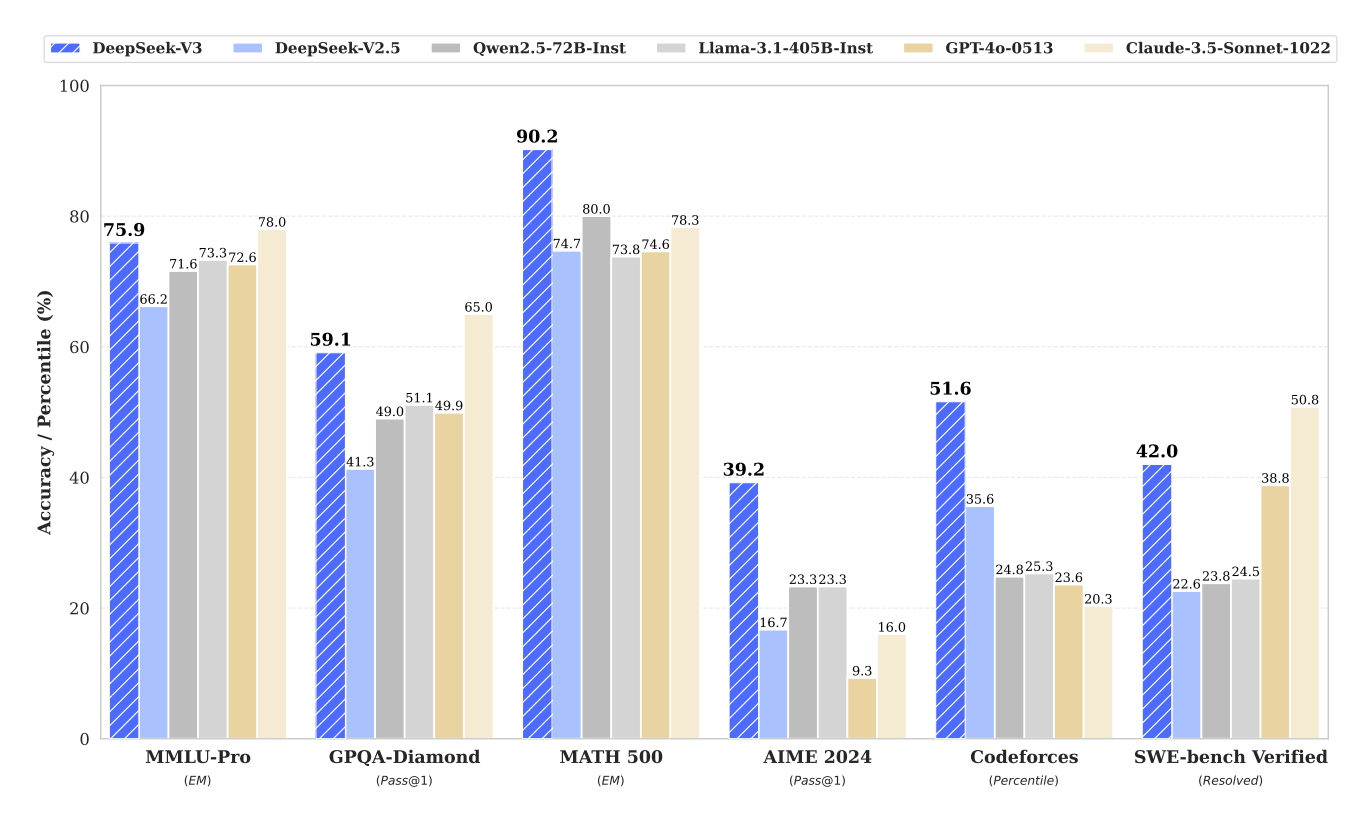
DeepSeek-V3
Summary: DeepSeek-V3 is a powerful Mixture-of-Experts (MoE) language model featuring 671 billion total parameters, with 37 billion activated for each token. Designed for efficient inference and cost-effective training, it incorporates Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were rigorously validated in its predecessor, DeepSeek-V2. Additionally, DeepSeek-V3 introduces an auxiliary-loss-free strategy for load balancing and employs a multi-token prediction training objective to enhance performance. Pre-trained on 14.8 trillion diverse and high-quality tokens, the model undergoes Supervised Fine-Tuning and Reinforcement Learning stages to fully realize its potential. Comprehensive evaluations demonstrate that DeepSeek-V3 surpasses other open-source models and achieves performance on par with leading closed-source counterparts. Despite its impressive capabilities, the model requires only 2.788 million H800 GPU hours for complete training. Furthermore, the training process is notably stable, with no irrecoverable loss spikes or rollbacks encountered throughout.
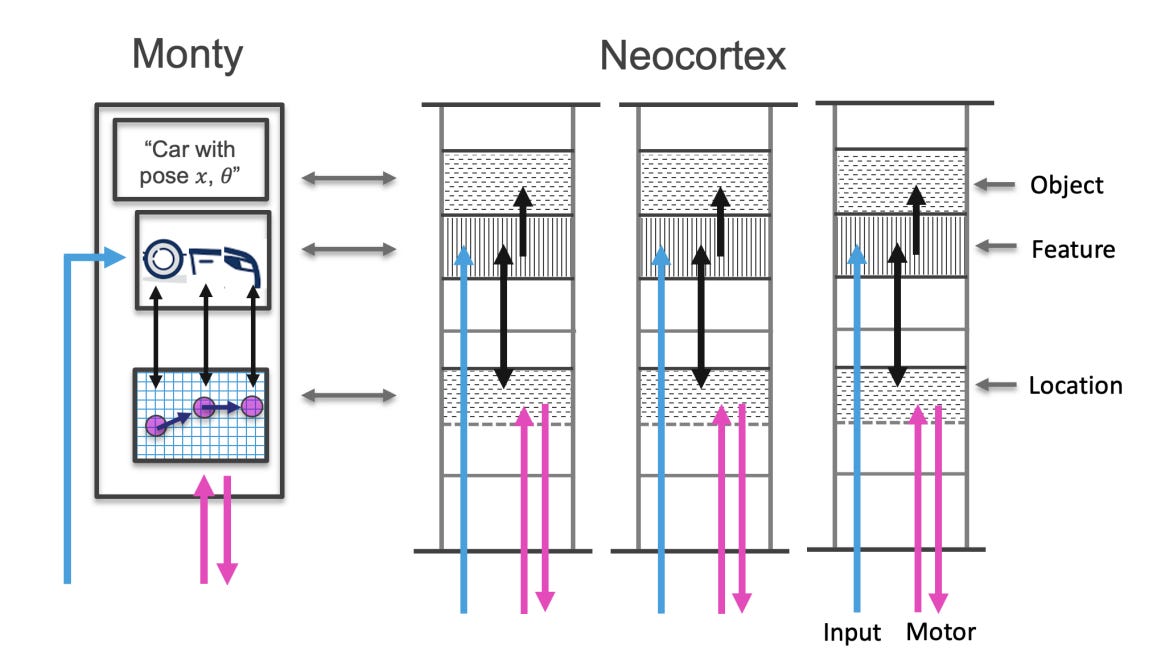
The Thousand Brains Project: A New Paradigm for Sensorimotor Intelligence
Summary: Artificial intelligence has advanced rapidly over the past decade, driven by larger deep-learning systems, yet creating systems that function effectively in diverse real-world environments remains a challenge. The Thousand Brains Project proposes an alternative approach to AI, inspired by the principles of the neocortex. It introduces a thousand-brains system, a sensorimotor agent capable of quickly learning a wide range of tasks and potentially replicating human neocortical capabilities. At its core are learning modules, modeled after cortical columns, which act as semi-independent units to model objects, encode spatial information, and estimate or effect movement. Learning is rapid and associative, similar to Hebbian learning, leveraging spatial biases for efficient continual learning. These modules interact through a "cortical messaging protocol" (CMP) to form abstract representations and integrate multiple modalities. The system’s design supports hierarchical and non-hierarchical interactions among modules. This architecture enables the creation of adaptive AI systems that learn and operate effectively in complex environments.
VidTwin: Video VAE with Decoupled Structure and Dynamics
Summary: Recent advancements in video autoencoders (Video AEs) have greatly enhanced video generation quality and efficiency. This paper introduces VidTwin, a compact and innovative video autoencoder that separates video into two latent spaces: Structure latent vectors for global content and movement, and Dynamics latent vectors for fine details and rapid motion. VidTwin uses an Encoder-Decoder backbone, supplemented by two specialized submodules for extracting these latent representations. The first submodule employs a Q-Former to capture low-frequency motion trends, combined with downsampling blocks to eliminate redundant details. The second submodule averages latent vectors spatially to focus on rapid motion. VidTwin achieves a high compression rate of 0.20% while maintaining excellent reconstruction quality, with a PSNR of 28.14 on the MCL-JCV dataset. It also performs effectively in downstream generative tasks, demonstrating both efficiency and scalability. The model offers explainability, aiding interpretation of video representations. VidTwin sets a benchmark for compact, high-quality video generation. Its design opens new directions for video latent representation and generative research.

DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation
Summary: Sora-like video generation models have made significant strides using the Multi-Modal Diffusion Transformer (MM-DiT) architecture. However, most existing models focus on single-prompt generation and struggle to create coherent scenes for multiple sequential prompts, which better reflect real-world dynamics. While early attempts at multi-prompt video generation exist, they face challenges such as strict data requirements, weak prompt adherence, and unnatural transitions. To overcome these issues, this paper introduces DiTCtrl, the first training-free multi-prompt video generation method designed for MM-DiT architectures. DiTCtrl approaches multi-prompt video generation as temporal video editing with smooth transitions. By analyzing MM-DiT’s attention mechanism, the method leverages 3D full attention, which behaves similarly to cross/self-attention in UNet-like diffusion models, to enable mask-guided semantic control across prompts with shared attention. This design ensures smooth transitions and consistent object motion across sequential prompts. DiTCtrl delivers high-quality, multi-prompt videos without requiring additional training, advancing the field of dynamic video generation.

Learning Flow Fields in Attention for Controllable Person Image Generation
Summary: Controllable person image generation focuses on producing images of individuals conditioned on reference images, enabling precise control over appearance and pose. Existing methods often sacrifice fine-grained textural details from the reference image, despite delivering high overall image quality. This distortion arises from inadequate attention to corresponding regions in the reference image. To tackle this, we propose Learning Flow Fields in Attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Leffa achieves this using a regularization loss applied to the attention map within a diffusion-based baseline. Extensive experiments demonstrate that Leffa sets a new benchmark in controlling appearance (e.g., virtual try-on) and pose (e.g., pose transfer), reducing fine-grained detail loss while preserving high image quality. Moreover, we show that the proposed loss function is model-agnostic and can enhance the performance of other diffusion models, making Leffa a versatile solution for controllable image generation.

Join 6,000+ investors who start their week with Money Machine Newsletter's insights to get smarter about investing in stocks. It's free, it's fast, it's a no brainer, just your weekly dose of market-beating stocks in a 5-minute read (LINK)