


Top AI Research Papers -June 2025
June 1 - June 16, 2025

Constructing and Evaluating Declarative RAG Pipelines in PyTerrier

Summary: This paper introduces PyTerrier-RAG, an extension to the PyTerrier platform designed to simplify the construction and evaluation of Retrieval-Augmented Generation (RAG) systems. It allows RAG to be formulated as a declarative pipeline, where components like retrievers and large language model readers can be easily combined and tested. Using PyTerrier's unique operator notation, users can succinctly build and modify complex pipelines to experiment with different architectures. The framework also provides easy access to standard RAG datasets, evaluation measures, and a wide range of state-of-the-art retrieval models. Ultimately, PyTerrier-RAG aims to accelerate research by allowing for the rapid and systematic comparison of various RAG pipeline components.
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
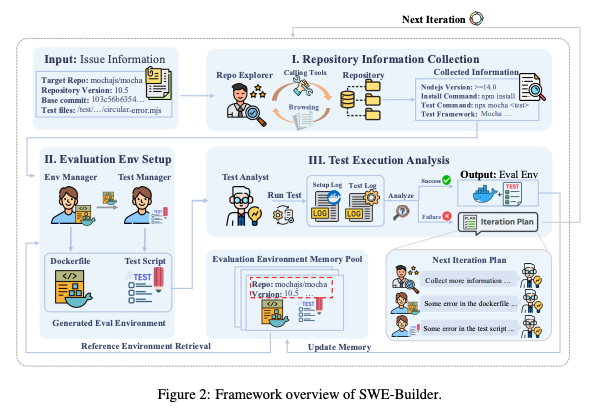
Summary: This paper introduces SWE-Factory, an automated pipeline designed to overcome the labor-intensive challenges of creating large-scale datasets for the GitHub issue resolution task. The system integrates a multi-agent
SWE-Builderfor environment setup, a standardized exit-code method for automatic grading, and a reliable process to validate fixes. Experimental results demonstrate the pipeline is highly effective and low-cost, with its grading achieving 100% accuracy and its validation process reaching 0.92 precision. The analysis also identifies an "error2pass" phenomenon where flawed tests pass incorrectly, revealing the necessity of filtering these cases for fair model evaluation. Ultimately, SWE-Factory aims to accelerate the collection of high-quality datasets to advance the training and benchmarking of AI in software engineering.
Ming-Omni: A Unified Multimodal Model for Perception and Generation

Summary: This paper proposes Ming-Omni, a unified multimodal model capable of processing and generating content across images, text, audio, and video within a single framework. It leverages dedicated encoders and a Mixture of Experts (MoE) architecture to efficiently process and fuse diverse inputs without task-specific fine-tuning. Uniquely, Ming-Omni excels at both perception and generation, integrating advanced decoders to produce high-quality speech and images. The authors claim it is the first open-source model to match the broad modality support of GPT-4o. By releasing all code and model weights, Ming-Omni provides a powerful, open solution for unified multimodal AI research and development.
CoRT: Code-integrated Reasoning within Thinking

Summary: This paper introduces CoRT, a post-training framework designed to address the mathematical weaknesses of Large Reasoning Models (LRMs) by teaching them to efficiently use a Code Interpreter. The core of the framework is a data synthesis method called "Hint-Engineering," which strategically inserts hints into text to guide the model on how to leverage external computational tools. Using this method, the researchers post-trained models from 1.5B to 32B parameters on a small set of high-quality, manually-created samples. Experimental results demonstrate that this approach yields significant gains, with up to an 8% absolute improvement on challenging math datasets. Furthermore, the resulting models are far more efficient, using 30-50% fewer tokens than their language-only counterparts.
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy

Summary: This position paper challenges the prevailing research focus on creating fully autonomous AI agents, citing significant issues with their reliability, transparency, and understanding of human needs. As a more effective path forward, it proposes LLM-based Human-Agent Systems (LLM-HAS), where the primary goal is collaboration rather than replacement. In this model, the human remains actively involved to provide guidance, clarify requirements, and maintain ultimate control over the system's actions. This human-in-the-loop approach results in systems that are more trustworthy, adaptable, and better aligned with actual user goals. Citing examples from fields like healthcare and finance, the paper argues that this human-AI synergy is more effective for complex tasks than AI acting alone. Ultimately, the authors contend that AI progress should be measured not by a system's independence, but by how well it enhances human capabilities through meaningful partnership.