Top AI Research Papers -Last Week
May 7 - May 14, 2025

Highlights
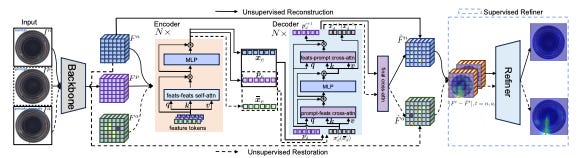
OneNIP enables multi-class anomaly detection by reconstructing anomalies from a single normal image prompt using transformer-based models.
Marigold repurposes latent diffusion models for dense vision tasks with minimal tuning and strong zero-shot performance.
BLIP3-o uses diffusion transformers and sequential pre-training to unify vision-language understanding and generation.
GovSim reproducibility shows large LLMs generalize cooperation across agents, languages, and environments.
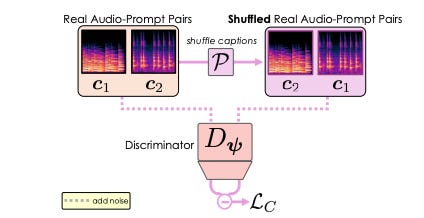
ARC accelerates diffusion-based text-to-audio synthesis using a contrastive adversarial objective without distillation.
Learning to Detect Multi-class Anomalies with Just One Normal Image Prompt
Summary: Self-attention-based reconstruction models often fail at anomaly detection due to over-reconstruction and low-resolution latent spaces. The proposed OneNIP method uses a single normal image prompt to reconstruct normal features and restore anomalies. This enables efficient and generalized unified anomaly detection with minimal input. A supervised refiner further improves pixel-level segmentation by regressing reconstruction errors from real and synthetic anomalies.
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
Summary: Deep learning success in vision has relied heavily on large labeled datasets and strong pre-trained models. Text-to-image latent diffusion models trained on massive captioned data have emerged as powerful visual foundations. This work introduces Marigold, a family of conditional generative models that adapt pretrained latent diffusion models for dense prediction tasks. Marigold achieves state-of-the-art zero-shot generalization with minimal architectural changes, using small synthetic datasets and modest compute.

BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Summary: Recent research has increasingly focused on unifying image understanding and generation in multimodal models. This work introduces BLIP3-o, a suite of unified models leveraging a diffusion transformer to generate semantically rich CLIP features, outperforming traditional VAE-based approaches. A sequential pre-training strategy, first on image understanding, then generation preserves interpretability while enhancing generative performance. The approach is supported by a high-quality instruction-tuning dataset, BLIP3o-60k and achieves state-of-the-art results.

Reproducibility Study of "Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents"
Summary: This study extends GovSim by validating that large LLMs like GPT-4-turbo sustain cooperation better than smaller models. It introduces new scenarios, heterogeneous agents, Japanese instructions, and inverse environments to test generalization. Results show strong models influence weaker ones toward cooperation. The findings highlight GovSim’s versatility and its relevance for building effective multi-agent AI systems.

Fast Text-to-Audio Generation with Adversarial Post-Training
Summary: Text-to-audio systems are often too slow for practical use in creative workflows. This work introduces ARC post-training, the first adversarial acceleration method for diffusion/flow models that doesn’t rely on distillation. ARC combines a relativistic adversarial loss with a novel contrastive discriminator to improve speed and prompt fidelity. Applied to Stable Audio Open, it enables generation of 12s of 44.1kHz stereo audio in 75ms on an H100, setting a new speed benchmark.